Rede Neural Convolucional (CNN)
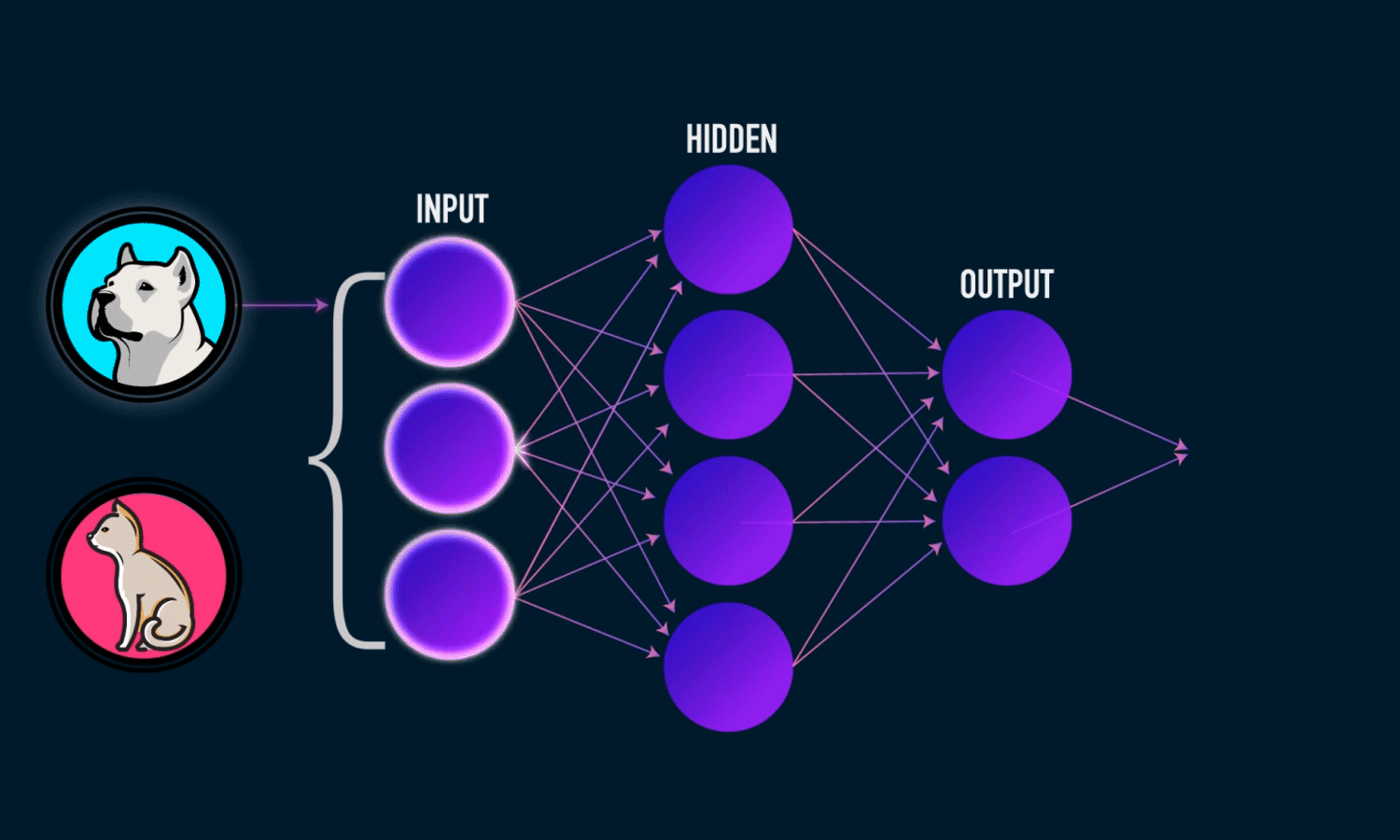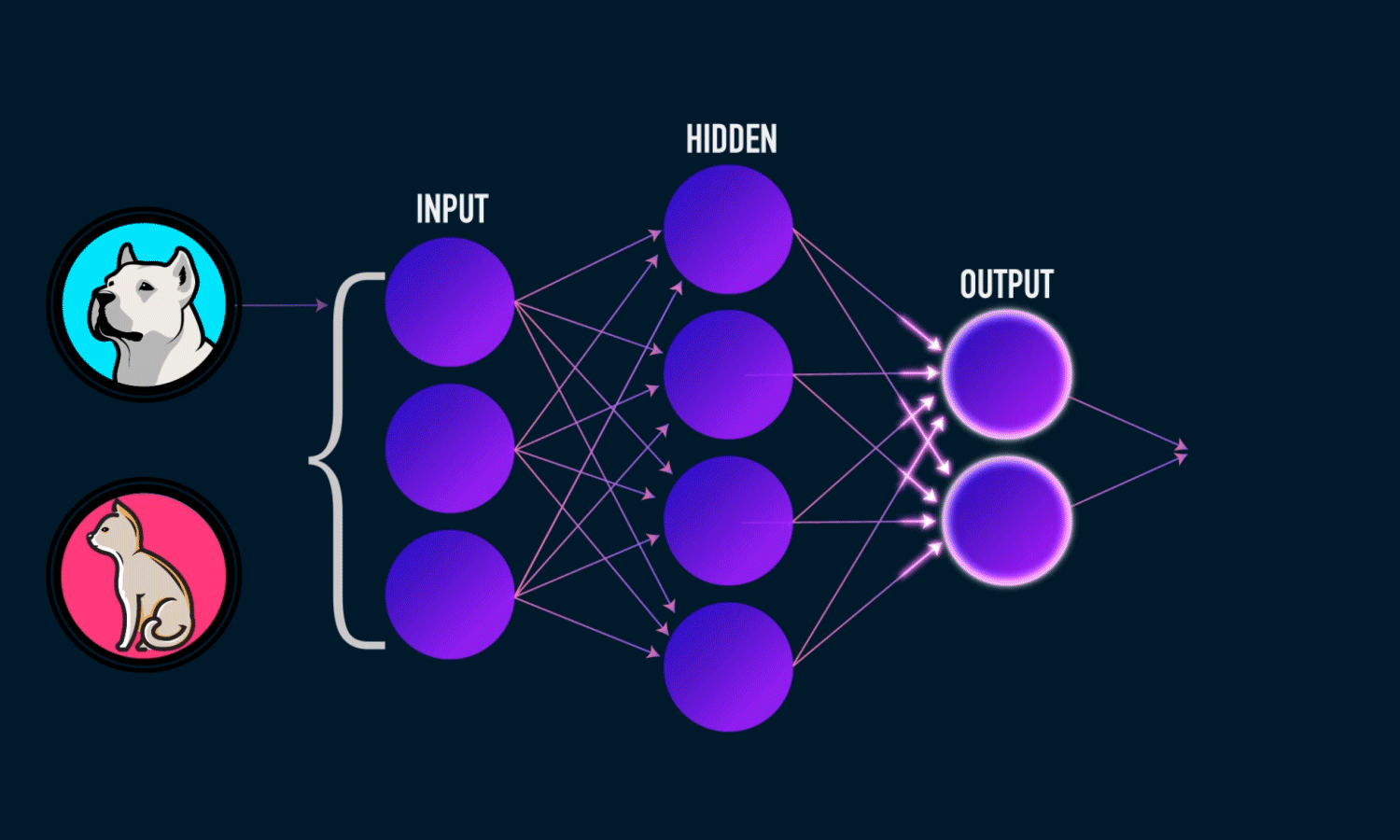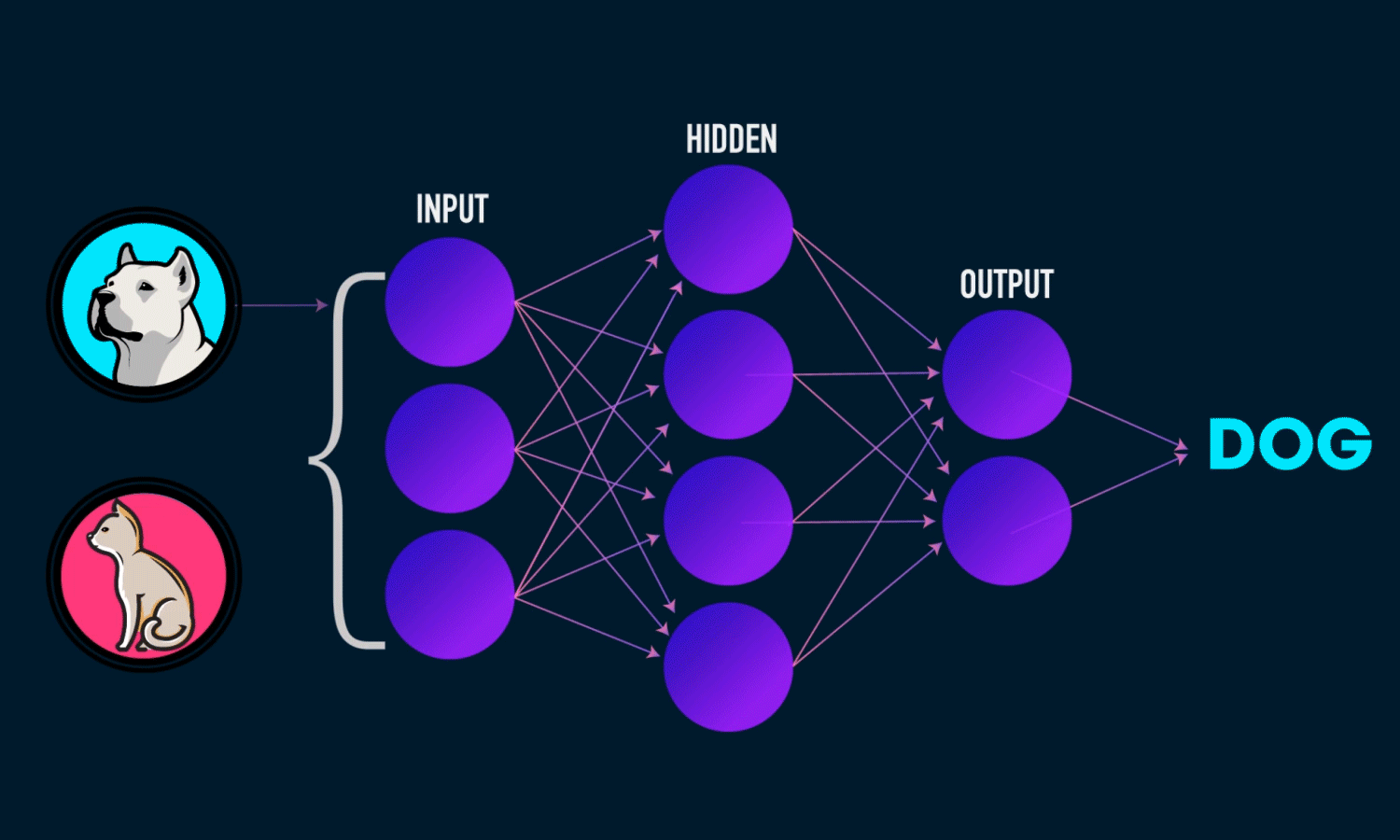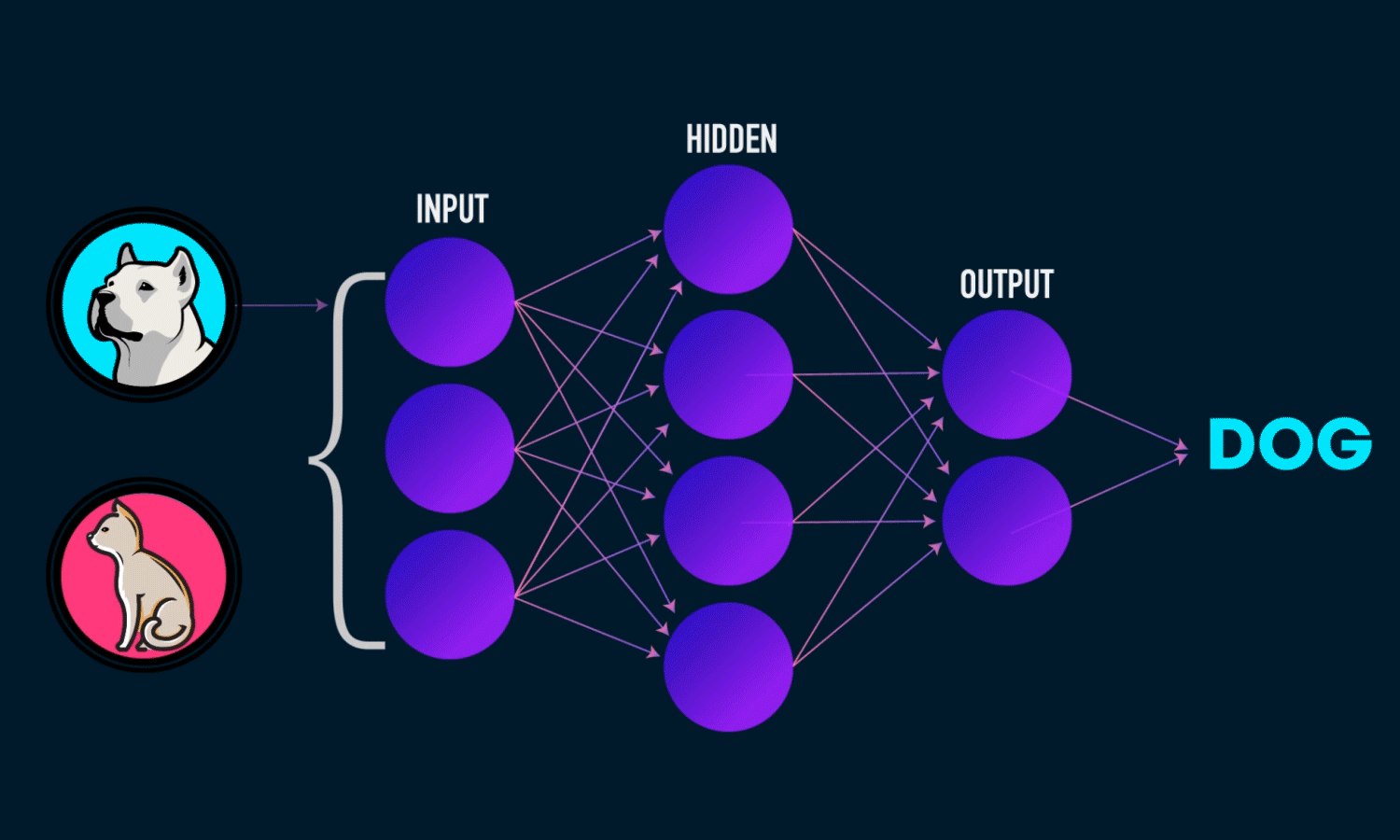
O que é Rede Neural Convolucional ?
Essa pergunta foi respondida um milhão de vezes, em quase todos os lugares da internet. Rede Neural Convolucional é “a class of Deep, Feed-Forward Artificial Neural Networks“!
O que? É simples assim? Estou brincando?
Não, não estou.
Mas a questão novamente – O que há de tão especial neles?
Bem, existem muitas características que os tornam especiais e ninguém pode dar uma resposta completa. Mas, já que você pediu, vou dar-lhe alguns. J
- As redes convolucionais têm a propriedade chamada ‘ Spatial Invariance ‘, o que significa que aprendem a reconhecer características da imagem em qualquer lugar da imagem. O pooling permite translação, rotação e invariância de escala (isso será explicado nas seções posteriores do blog).
A invariância espacial pode ser entendida por um exemplo simples – imagine que você tem um detector de rosto para cachorro. Ao identificar características como orelhas, nariz e boca de um cachorro, você poderá identificar o rosto. O detector facial de seu cão dispara sempre que houver orelha, nariz e boca de um cão na região do detector. Não importa onde você vê um recurso, desde que você o veja em algum nível. - ‘ Parameter Sharing ‘ – Compartilhamento de pesos por todos os neurônios em um mapa de características particular. Ele permite que a rede procure um determinado recurso em qualquer lugar da imagem, em vez de apenas em uma área específica.
- Local connectivity – conceito de cada neural conectado apenas a um subconjunto da imagem de entrada (ao contrário de uma rede neural onde todos os neurônios estão totalmente conectados). Em uma rede convolucional, cada neurônio só recebe entrada de um pequeno grupo local de pixels na imagem de entrada. Isso implica que todas as entradas que vão para um determinado neurônio estão realmente próximas umas das outras. Esse recurso na Rede Neural Convolucional faz a suposição de localidade e, portanto, é mais poderoso. Porque, como dizem, suposições mais fortes dão melhores resultados.
OK, já vimos o suficiente de suas características. Agora, vamos ver como funciona?
Como funciona?
Vamos entender o conceito com um exemplo.
Considere um problema de identificação de imagem usando Rede Neural Convolucional. Suponha que haja uma imagem representada por meio de valores de pixel (cada imagem pode ser considerada como uma matriz de valores de pixel). Nesse caso, suponha que nossa imagem possa ser representada por uma matriz 5 * 5.

A próxima coisa que você faz é pegar um filtro 3 * 3 (que é outra matriz) e deslizar sobre a imagem completa e, ao longo do caminho, pegar o produto escalar entre o filtro e os pedaços da imagem de entrada.

Aqui, uma coisa que vale a pena notar é que a matriz 3 × 3 “vê” apenas uma parte da imagem de entrada em cada passada (o que é uma passada? – veremos isso mais tarde). Na terminologia da Rede Neural Convolucional, esta matriz 3 × 3 é chamada de ‘ filter‘ ou ‘kernel’ e a matriz formada deslizando o filtro sobre a imagem e computando o produto escalar é chamada de ‘ Convolved Feature‘ ou ‘ Feature Map‘ .
É importante observar que os filtros atuam como detectores de recursos da imagem de entrada original. É bastante óbvio que valores diferentes da matriz de filtro produzirão mapas de recursos diferentes para a mesma imagem de entrada. Aqui está um exemplo – dependendo do tipo de operação que você deseja realizar em uma imagem específica, você usa diferentes tipos de filtro (ou seja, os valores dentro da matriz 3 * 3 serão alterados). Por exemplo, para operação de detecção de borda, você pode observar valores negativos na matriz de filtro, enquanto para operação de desfoque todos os valores são positivos.

CNN aprende os valores desses filtros por conta própria durante o processo de treinamento. No entanto, precisamos fornecer algumas informações de antemão, como número de filtros, tamanho do filtro etc. Quanto mais filtros usarmos, mais recursos de imagem serão extraídos e melhor será nossa rede no reconhecimento de padrões em imagens não vistas.
Alguns parâmetros de extração de recursos que você precisa entender são:
Depth: a profundidade corresponde ao número de filtros que usaremos para a operação de convolução. Para diferentes operações, diferentes filtros são usados.
Stride: Stride é o número de pixels pelos quais deslizamos nossa matriz de filtro sobre a matriz de entrada. Uma distância de 1 significa que moveremos os filtros um pixel de cada vez.
Zero-padding: A matriz de entrada é preenchida com zeros ao redor da borda, para que possamos aplicar o filtro aos elementos vizinhos da matriz da imagem de entrada. Ele garante que o filtro cubra toda a área da imagem de entrada.
Lidando com a non-linearity: após cada camada convolucional, é uma convenção geral aplicar uma camada não linear (ou camada de ativação ) imediatamente após. A razão disso é que a convolução é uma operação linear (multiplicações e somas por elemento) e este não é o caso nos problemas da vida real, portanto, consideramos a não linearidade introduzindo uma função não linear. Na maioria dos casos, as pessoas preferem usar a função ReLU (Rectified Linear Unit) não linear. Tanh e Sigmóide são outras funções não lineares populares.
Camadas de pool: Ittambém é conhecida como camada de amostragem inferior. A camada de pooling é usada para reduzir o tamanho espacial da representação de forma que a quantidade de parâmetros e computação na rede possa ser reduzida. A camada de pooling opera em cada mapa de feições independentemente.
O tipo mais comum de pooling usado é o pooling máximo. Isso basicamente leva um filtro (normalmente de tamanho 2 × 2) e uma passada do mesmo comprimento. Em seguida, ele o aplica ao volume de entrada e produz o número máximo em cada sub-região em que o filtro se transforma.

Rede totalmente conectada: Convolução, ReLU e Pooling funcionam para fins de extração de recursos. Essas camadas são os blocos de construção básicos de qualquer rede neural convolucional. Mas a ideia por trás de extrair esses recursos é classificar a imagem ou qualquer outro propósito para esse assunto, e é por isso que precisamos de uma rede neural totalmente conectada. Em outras palavras, uma camada totalmente conectada leva uma soma ponderada de pixels em toda a entrada para essa camada.
A camada Fully Connected é um Perceptron Multi-Layer tradicional que usa uma função de ativação softmax (ou qualquer outra função como sigmóide) na camada de saída. O termo “Totalmente Conectado” implica que todos os neurônios da camada anterior estão conectados a todos os neurônios da próxima camada. A outra maneira de entender isso é, pense assim, que as camadas convolucionais extraem recursos de alto nível e as camadas totalmente conectadas decidem a função não linear desses recursos.
Finalmente; A retropropagação é usada para calcular os gradientes do erro em relação a todos os pesos na rede e usar a descida do gradiente para atualizar todos os pesos de filtro e valores de parâmetro para minimizar o erro de saída.
LeNet, AlexNet, VGGNet são algumas redes neurais convolucionais famosas. Aconselho você a explorá-los.

Por que as camadas totalmente conectadas são usadas no “final” dos NNs convolucionais? Por que não antes?
Depois que uma camada totalmente conectada é aplicada, a saída é “embaralhada”, ou seja, não tem estrutura espacial. A ideia de uma camada convolucional é encontrar a estrutura local em cada parte da entrada. Somente quando há alguma estrutura espacial ou quase espacial na entrada, a camada convolucional pode ser aplicada e, portanto, não faz sentido aplicar a camada totalmente conectada primeiro e a camada de convolução depois. Não é?
Portanto, a ordem geral seguida na Rede Neural Convolucional é a camada convolucional, a unidade não linear, o pool máximo ou qualquer outra camada de pooling e, finalmente, a camada totalmente conectada.
Rede totalmente convolucional (FCN) – camada totalmente conectada em uma rede neural profunda e uma camada convolucional equivalente:
nos últimos anos, surgiu a ideia de rede totalmente convolucional. A principal diferença que possui da rede neural convolucional tradicional é que a rede totalmente convolucional está aprendendo filtros em todos os lugares, até mesmo as camadas de tomada de decisão no final da rede atuam como filtros. Uma rede totalmente convolucional tenta aprender representações e tomar decisões com base na entrada espacial local (no entanto, captura o contexto global) em vez da entrada espacial global.
Nesta seção, tentaremos ver a vantagem básica que uma rede neural convolucional tem sobre uma rede neural totalmente conectada. Em uma camada convolucional, o número de parâmetros a serem ajustados é menor devido ao fato de que os pesos são compartilhados em uma camada convolucional.
Além disso, o Max Pooling pode ser usado logo após uma camada convolucional para reduzir a dimensionalidade da camada. Considere também que se uma grande imagem de entrada deve ser processada, então toda a rede neural totalmente conectada teria que ser digitalizada sobre a imagem grande, isso não é eficiente, portanto, se as camadas totalmente conectadas forem convertidas em suas camadas de convolução equivalentes, então apenas uma única passe para frente é suficiente.
Todas essas coisas levam a um modelo eficiente e robusto. Esta é a razão pela qual a rede totalmente convolucional está se tornando popular a cada dia.
Redes neurais escassamente conectadas:
redes neurais profundas e redes neurais convolucionais têm recebido atenção considerável nos dados comunidade científica devido à sua capacidade de extrair e representar abstrações de alto nível em conjuntos de dados. Eles podem ser aplicados a uma ampla gama de tarefas de reconhecimento e classificação, porém ao custo de um grande número de parâmetros e complexidade computacional. O alto consumo de energia devido ao seu alto grau de complexidade sempre foi motivo de preocupação.
O consumo de potência / energia das redes neurais é dominado por acessos à memória, a maioria dos quais ocorre em redes totalmente conectadas. Com o uso de redes conectadas esparsamente, o número de conexões em redes totalmente conectadas pode ser reduzido em até 90%, mantendo a precisão e o desempenho.
Uma abordagem surpreendentemente eficaz para fazer isso é simplesmente reduzir o número de canais em cada camada convolucional por uma fração fixa e treinar novamente a rede. Em muitos casos, isso leva a redes significativamente menores, com apenas alterações mínimas de precisão. A esparsidade máxima é obtida explorando a redundância inter-canal e intra-canal, com uma etapa de ajuste fino que minimiza a perda de reconhecimento causada pela maximização da esparsidade.

Acho que cobrimos quase tudo o que é necessário para um entendimento básico de Redes Neurais Convolucionais. Isso deve ser bom o suficiente para dar o primeiro passo em direção à construção de nosso modelo de Rede Neural Convolucional.
É isso por hoje.
Aprendeu algo? Compartilhe com seus amigos.
Via: