As 5 Principais diferenças entre ETL vs ELT
Nas últimas décadas, o ETL (extrair, transformar, carregar) tem sido a abordagem tradicional para armazenamento e análise de dados. A abordagem ELT (extrair, carregar, transformar) muda o antigo paradigma. Mas, o que realmente acontece quando o “T” e o “L” são trocados?
ETL e ELT resolvem a mesma necessidade:
Bilhões de dados e eventos precisam ser coletados, processados e analisados pelas empresas. Os dados precisam estar limpos, gerenciáveis e prontos para análise. Precisa ser enriquecido, moldado e transformado. Para torná-lo significativo.
Mas, o “ como ” é o que é diferente e leva a novas possibilidades em muitos projetos de dados modernos. Existem diferenças em como os dados brutos são gerenciados, quando o processamento é feito e como a análise é realizada.
Neste artigo, demonstraremos as diferenças tecnológicas de ETL e ELT, mostrando exemplos de engenharia e análise de dados das duas abordagens e resumindo 10 prós e contras de ETL e ELT .
As diferenças tecnológicas: vamos primeiro alinhar os 3 estágios – E, T, L:
- Extração : recuperar dados brutos de um pool de dados não estruturado e migrá-los para um repositório de dados temporário
- Transformação : Estruturar, enriquecer e converter os dados brutos para corresponder à fonte de destino
- Carregando : Carregando os dados estruturados em um data warehouse para serem analisados e usados por ferramentas de business intelligence (BI)
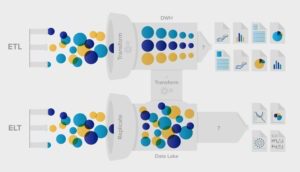
ETL vs. ELT: O que é ETL?
O ETL requer gerenciamento dos dados brutos, incluindo a extração das informações necessárias e a execução das transformações corretas para atender às necessidades de negócios. Cada estágio – extração, transformação e carregamento – requer interação de engenheiros e desenvolvedores de dados e lidar com as limitações de capacidade de data warehouses tradicionais. Usando ETL, analistas e outros usuários de BI se acostumaram a esperar , já que o simples acesso às informações não está disponível até que todo o processo de ETL seja concluído..jpg)
O que é ELT?
Na abordagem ELT, depois de extrair seus dados, você inicia imediatamente a fase de carregamento – movendo todas as fontes de dados em um único repositório de dados centralizado. Com as tecnologias de infraestrutura atuais que usam a nuvem, os sistemas agora podem oferecer suporte a grande armazenamento e computação escalonável. Portanto, um grande conjunto de dados em expansão e processamento rápido é virtualmente infinito para manter todos os dados brutos extraídos.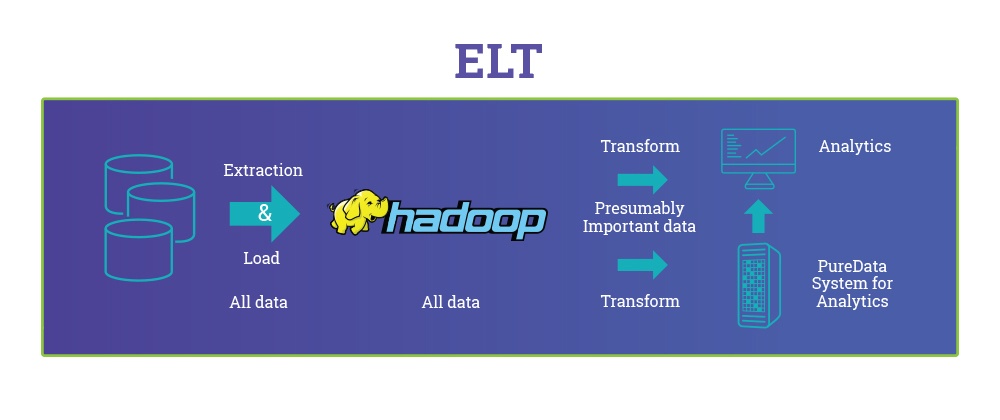 Dessa forma, a abordagem ELT oferece uma alternativa moderna ao ETL . No entanto, ainda está evoluindo. Portanto, as estruturas e ferramentas de suporte ao processo ELT nem sempre são totalmente desenvolvidas para facilitar o carregamento e o processamento de grande quantidade de dados. O lado positivo é muito promissor –permitindo acesso ilimitado a todos os seus dados a qualquer momento e economizando esforços e tempo dos desenvolvedores para analistas e usuários de BI .
Dessa forma, a abordagem ELT oferece uma alternativa moderna ao ETL . No entanto, ainda está evoluindo. Portanto, as estruturas e ferramentas de suporte ao processo ELT nem sempre são totalmente desenvolvidas para facilitar o carregamento e o processamento de grande quantidade de dados. O lado positivo é muito promissor –permitindo acesso ilimitado a todos os seus dados a qualquer momento e economizando esforços e tempo dos desenvolvedores para analistas e usuários de BI .
Um exemplo prático
Aqui está um exemplo para ilustrar as diferenças tecnológicas entre ETL e ELT e detalhar os detalhes.
Nossa demonstração usará duas tabelas de dados : uma para compras e outra para moedas, conforme abaixo:
TABELA DE COMPRAS
| ip | montante | moeda |
|---|---|---|
| 2.248.0.0 | 100 | EURO |
| 2.248.0.0 | 200 | GBP |
| 72.229.28.185 | 300 | USD |
TABELA DE MOEDAS
| moeda | taxa |
|---|---|
| EURO | 1,12 |
| GBP | 1,3 |
| USD | 1 |
Para entender os fundamentos, veremos como este exemplo é processado em ETL e ELT . Para cada um, mostraremos como calcular uma única tabela de resumo usando essas duas tabelas – incluindo a compra média por país (com base no endereço IP fornecido).
Transformação de dados ETL em dados extraídos
No processo ETL, o estágio de transformação se aplica a uma série de regras ou funções nos dados extraídos para criar a tabela que será carregada.
Aqui está um código para demonstrar o processo preliminar de transformação de dados para ETL:

Usando este script, estamos mapeando os endereços IP para seus respectivos países. Estamos derivando um novo valor calculado ‘montante’ multiplicando os valores de ambos os grupos de tabelas de origem por atributo de moeda. Em seguida, estamos classificando os dados pela coluna do país, juntando os dados das tabelas de compras e moedas e somando os valores médios por país.
Essa transformação de dados resulta em uma nova tabela com o valor médio por país:
AMOUNT MÉDIO POR PAÍS
| país | montante |
|---|---|
| EUA | 300 |
| SUÉCIA | 372 |
Transformação de dados ELT em tempo de execução de consulta
Em contraste com ETL, com ELT todos os dados já estão carregados e podem ser usados a qualquer momento.
Portanto, a transformação é feita no tempo de execução da consulta:

Na consulta, selecionamos o endereço IP por país, multiplicando o valor da tabela de compras e a taxa da tabela de moedas para calcular o valor médio. Em seguida, juntando as duas tabelas com base nas colunas comuns de ambas as tabelas e agrupando por país.
Isso resultará na mesma tabela de saída exata do processo ETL acima. No entanto, neste caso, como todos os dados brutos foram carregados, podemos mais facilmente continuar executando outras consultas no mesmo ambiente para testar e identificar as melhores transformações de dados possíveis que correspondem aos requisitos de negócios.
A linha de fundo deste exemplo prático –
ELT é mais eficiente do que ETL para código de desenvolvimento . Além disso, o ELT é muito mais flexível do que o ETL. Com o ELT, os usuários podem executar novas transformações, testar e aprimorar consultas diretamente nos dados brutos conforme necessário – sem o tempo e a complexidade com os quais nos acostumamos com o ETL.
Gerenciando Data Warehouses e Data Lakes
De acordo com o Gartner , as necessidades de gerenciamento e integração de dados das empresas hoje exigem dados pequenos e grandes, não estruturados e estruturados . Aqui está o que eles sugerem sobre o que precisa ser mudado na maneira de trabalhar:
“A equipe de BI tradicional precisa continuar desenvolvendo melhores práticas claras, com objetivos de negócios bem compreendidos … há um segundo modo de BI que é mais fluido e … altamente iterativo com descoberta de dados imprevistos e que podem falhar rapidamente.”
“The traditional BI team needs to continue developing clear best practices, with well understood business objectives… there is a second mode of BI which is more fluid and … highly iterative with unforeseen data discovery and is allowed to fail fast.”
Essa frase gerou muita conversa sobre data warehouses versus data lakes. O conceito de data lake é uma nova maneira de pensar sobre big data para dados não estruturados feitos para escala infinita – usando ferramentas como o Hadoop para implementar o segundo modo de trabalho de BI descrito pelo Gartner. No entanto, embora as empresas ainda usem data warehouses para oferecer suporte a um paradigma tradicional, como ETL, data warehouses modernos e escalonáveis, como Redshift e BigQuery, podem ser usados para implementar o paradigma moderno de ELT com todos os seus benefícios inerentes mencionados acima.
A IBM fala sobre 5 coisas que os projetos modernos de big data exigem – mostrando a necessidade de novos conceitos de dados, como o data lake.
São os 5 V’s:
- Volume: o volume de dados (brutos)
- Variedade: a variedade (por exemplo, estruturada, não estruturada, semiestruturada) de dados
- Velocidade: a velocidade de processamento de dados, consumação ou análise de dados
- Veracidade: o nível de confiança nos dados
- (Valor): o valor por trás dos dados
ETL continua a ser uma boa combinação ao lidar com data warehouses legados – olhando para subconjuntos menores e movendo-os para o data warehouse. Mas é difícil fornecer uma solução com ETL para os 5 V conforme você avança na lista – como lidar com os volumes? Os dados não estruturados? Rapidez? etc.
A abordagem ELT abre oportunidades para trabalhar em um ambiente de BI mais fluido e iterativo devido à sua eficiência e flexibilidade. A ELT permite a implementação de muitos conceitos de data warehouse e se estende a conceitos de data lake – permitindo a incorporação de dados não estruturados em sua solução de BI.
Considerações finais sobre ETL e ELT
ETL está desatualizado. Isso ajudou a lidar com a limitação das infraestruturas tradicionais rígidas e de data center que, com a nuvem, isso não é uma barreira hoje. Em organizações com grandes conjuntos de dados de apenas alguns terabytes, o tempo de carregamento pode levar horas, dependendo da complexidade das regras de transformação.
ELT é uma parte importante do futuro do armazenamento de dados. Com o ELT, empresas de qualquer tamanho podem capitalizar nas tecnologias atuais. Ao analisar grandes pools de dados com mais agilidade e menos manutenção, as empresas obtêm insights importantes para criar vantagens competitivas reais e se destacar em seus negócios.
via: panoply