
O que são Deepfakes?
… E QUÃO PROFUNDOS ELES SÃO?
O termo “Deepfake” tornou-se popular de 2017 a 2018. Por volta dessa época, foram publicados clipes em que o rosto da pessoa A era colocado no corpo da pessoa B. A capacidade de fazer isso despertou grande interesse, especialmente devido ao código aberto natureza de alguns programas e algoritmos usados.
Com mais e mais Deepfakes surgindo na internet nos anos seguintes, aqueles que elogiavam a tecnologia e prometiam avanços e possibilidades rápidos foram recebidos com aqueles que expressaram sérias preocupações. Mudar o rosto soa como um poder assustador para qualquer um – certamente nada de terrível acontecerá, certo?
O PROBLEMA INEVITÁVEL
Quando uma nova tecnologia é introduzida – qual é a primeira aplicação que a humanidade pode pensar? Claro, é pornografia.
Assim que os recursos necessários para produzir Deepfakes se tornaram mais acessíveis, muitos sites apareceram com um catálogo crescente de Deepfaked Adult-Content. O que parece moderadamente preocupante a princípio acabou se revelando um tópico muito mais sério do que se pensava inicialmente. O problema em questão é: Consentimento.
Mulheres (e às vezes, embora muito raramente homens) estão sendo colocadas em conteúdo questionável sem sua permissão. Conteúdo, veja bem, que pode destruir ou prejudicar gravemente a carreira de alguém, como provou o vazamento massivo de fotos e vídeos pessoais, com o nome de bom gosto “The Fappening”. Mas agora você não precisa mais de uma falha de segurança em alguns servidores para colocar as mãos em conteúdo obsceno de pessoas famosas. A tecnologia para forjar o seu próprio agora estava ao alcance de todos.
No momento em que escrevi isso, só pude descobrir que o estado da Virgínia baniu a pornografia Deepfaked diretamente, com a China banindo totalmente Deepfakes não divulgados. Mas mesmo que não seja explicitamente coberto por lei, a prática pode levar a punições. Em maio de 2018, um britânico foi multado em 5.000 libras britânicas e passou 16 semanas na prisão por fazer fotos de um estagiário em fotos reveladoras (fonte) . No Reino Unido e em alguns outros países, é razoável presumir que a prática de Deepfaking alguém em pornografia é punível por lei, uma vez que viola sua privacidade, direito às suas próprias fotos e identidade e pode ser considerada como abuso sexual.
Com esse lado deprimente dos Deepfakes fora do caminho, vamos mergulhar na criação do nosso próprio (seguro para o trabalho) Deepfake. Gostaria de observar que ainda estou aprendendo e não sou, de forma alguma, um especialista no assunto.
Começando
Para começar, precisamos entender o que precisamos para criar um Deepfake com sucesso. Vamos começar com os dados: para cada Deepfake, deve haver uma origem e um destino . Você pode pensar nisso como a fonte da qual recortamos o rosto e colamos no destino.
Extraindo
Para extrair os frames, estarei usando o ffmpeg. Resumindo, ffmpeg é uma coleção de codecs e comandos que permitem converter arquivos de vídeo-imagem e áudio em diferentes formatos e variações. Nosso objetivo é converter nosso SOURCE -vídeo que baixamos (presumivelmente um .mp4, .mov, .mkv, .avi ou algo semelhante) em uma sequência de imagens, já que o algoritmo deepfake que usaremos só funciona com imagens . Para fazer isso, use este tipo de código dentro do seu prompt de comando (cmd para Windows, terminal para MacOS):
“ Ffmpeg -i input.mp4 -r 5 -output% 04d.png”
Eu sei, isso parece intimidante no início, mas vamos decompô-lo:
“Ffmpeg -i” diz ao ffmpeg para começar a converter algo. “Input.mp4” é o nosso vídeo, que queremos dividir em imagens individuais. Depois de ir para a pasta que contém o vídeo (usando “ caminho do cd ”), substitua esta parte pelo nome do vídeo que você baixou. Em seguida, “-r 5” simplesmente diz ao ffmpeg para definir a taxa de quadros para 5, o que significa 5 quadros por segundo. Ter a taxa de quadros completa de um vídeo (geralmente 30-60) dividida em imagens únicas aumenta o espaço necessário e nem sempre é necessário para deepfaking. Se você tiver muito pouca filmagem de sua fonte, deixe de fora este comando para extrair cada quadro. A nomenclatura estranha da saída “output% 04d” diz ao ffmpeg para usar 4 dígitos após o nome do arquivo e contar os quadros, resultando em um formato como “coolsource0001, coolsource0002, coolsource0003…” etc.
Agora, faremos o mesmo com o vídeo DESTINATION .
Para o vídeo- fonte , use uma taxa de quadros entre 5 e 15 , dependendo de quanto material você tem, para terminar com pelo menos 20.000 imagens.
No entanto, para o vídeo de destino , você precisa usar a taxa de quadros completa , conforme exigido pela maioria dos algoritmos deepfake. Assim, usamos este comando para o Vídeo-Destino:
“ Ffmpeg -i input.mp4 -output% 04d.png ”
Deixamos intencionalmente o comando “-r 5”, que usamos para limitar a taxa de quadros. Assim, o ffmpeg irá extrair cada quadro da nossa entrada.
DeepFaceLab
Em seguida, precisaremos das bibliotecas e algoritmos reais usados para criar um Deepfake. Atualmente (21-01-2021), a maneira mais convincente e rápida de criar um Deepfake é com “Deepfacelab”. Ele é compartilhado por “iperov” no github e pode ser acessado aqui .
Para baixar o DeepFaceLab , role para baixo até chegar a “Releases”. Aqui, você pode escolher a versão mais recente para o sistema operacional com o qual está trabalhando. Eu recomendo fortemente usar o Windows com uma placa de vídeo Nvidia, já que DeepFaceLab funciona muito bem com CUDA (que é exclusivo para GPUs Nvidia até onde eu sei).
Depois de baixar a versão adequada, você deseja instalar todos os pacotes que vêm com o download. Além disso, (se você estiver usando uma GPU Nvidia), você definitivamente deve instalar o CUDA e o cuDNN mais recente .
Quando ambos estiverem instalados, você precisa entrar na pasta “cuda” baixada, entrar na pasta “ bin” e copiar o “ cudnn64_7.dll ”. Em seguida, vá para “C: \ Arquivos de programas \ NVIDIA GPU Computing Toolkit \ CUDA \ v9.0 \ bin” e cole o arquivo lá. (Não tenho certeza se este é um requisito absoluto. A última etapa foi tirada do vídeo do tech 4tress sobre a instalação do DFL.
Isolando rostos
Ao abrir a versão baixada do DeepFaceLab, somos recebidos com duas pastas, a saber “ _internal ” e “ espaço de trabalho ”, bem como muitos Batch-Files. Esses arquivos basicamente executam certos comandos no console e executam scripts python específicos, o que torna um pouco mais agradável trabalhar com o DeepFaceLab. Vamos abrir e olhar para
- _interno
A pasta _internal contém todas as bibliotecas e scripts usados para o processo Deepfaking. Geralmente não há razão para alterar ou acessar nada nele. Então, vamos prosseguir para
É aqui que a mágica acontece. Se você abrir a pasta do espaço de trabalho, poderá ver:
- data_dst
- data_src
- Model
Também pode haver dois arquivos .mp4 incluídos, chamados “datasrc” e “datadst”. Estes são arquivos de amostra e podem ser excluídos. “Data_dst” é uma abreviatura de data_destination. O mesmo para “data_src” que significa data_source.
Dentro de cada pasta dst e src, é necessário que haja nossos quadros extraídos de nossa FONTE e DESTINATION-Video respectivamente, então apenas copie-os.
Assim que terminarmos com isso, iremos isolar os rostos.
Na minha experiência, o método mais rápido e preciso de extrair rostos é usando S3FD. Basta executar:
“ 4.) data_src extract faces S3FD best GPU.bat ”
“ 5.) data_dst extract faces S3FD best GPU.bat ”
Isso deve abrir seu prompt de comando e executar o processo de extração, como na imagem à direita.
Feito isso, volte para nossas pastas “data_src” e “data_dst”. Dentro de cada um deles, devemos encontrar uma nova pasta chamada “alinhado”. Chama-se assim porque o extrator facial alinha cada rosto, de forma que olhos, nariz e boca fiquem sempre no mesmo lugar para cada imagem. No entanto, o extrator facial não é perfeito e requer alguns exames manuais.
Eu recomendo percorrer a enorme pilha de arquivos no explorador de janelas e procurar por grandes pedaços de imagens inúteis – às vezes, as fotos não incluem o nosso assunto, então todas têm que ser excluídas. Esta é uma etapa muito importante, pois pode arruinar o treinamento de um modelo por ter apenas cerca de uma dúzia de imagens falsas em sua pasta.
Classificação de rostos
Depois de excluirmos grandes pedaços de faces inutilizáveis, ainda precisamos fazer uma limpeza. O motivo é que S3FD, o algoritmo de reconhecimento de face (suponho que seja o algoritmo, pois é nomeado no script em lote) não é totalmente perfeito. Às vezes, pode extrair o rosto de uma forma grosseira e contorcida, ou o rosto de outra pessoa ou mesmo nenhum rosto.
No entanto, passar por cada rosto manualmente é uma quantidade absurda de trabalho, considerando que nosso objetivo é um mínimo de 20 mil imagens para cada pessoa. É aqui que nossos algoritmos de classificação começam a brilhar. Basta executar esses arquivos em lote a partir da pasta-mestre:
“ 4.2.2) data_src classificar por histograma semelhante”
“ 5.2) data_dst classificar por histograma semelhante”
Essencialmente, isso agrupará os rostos por sua semelhança. Se rostos de outras pessoas forem incluídos, eles serão agrupados em grandes blocos e será mais fácil excluí-los. Percorra a pasta mais uma vez e seja o mais completo que deseja.

Treinando o modelo
Agora chegamos às coisas interessantes. Temos todos os nossos dados armazenados e classificados corretamente, o que significa que podemos chegar ao treinamento real do modelo. Para fazer isso, basta executar:
“ 6) treinar SAEHD.bat ”
SAEHD é, no momento em que este artigo foi escrito, o mais novo e melhor algoritmo da DeepFaceLab que permite um treinamento rápido e preciso. Ao executar o arquivo, serão solicitadas algumas coisas no console. Aqui estão as configurações que usei e os motivos:
- Resolução: 128 -> Treinei com uma GTX970, então 128 era uma resolução razoável.
- face_type: f -> “f” que significa “full”, pois queremos treinar as faces completas.
- learn_mask: y -> queremos aprender a máscara, uma vez que corta o rosto da maneira certa.
- optimizer_mode: 2/3 -> Modo 1 usa apenas VRAM do GPU, mas 2 e 3 também usam memória do sistema.
- arquitetura: df -> apenas df é compatível com “trueface” (torna-se mais importante posteriormente)
- ae_dims: 512 -> Pode ser reduzido se você ficar sem memória (para 256)
- ed_ch_dims: 21 -> Pode ser reduzido se você ficar sem memória.
- random_warp: y -> distorce as imagens aleatoriamente, produzindo melhores resultados da experiência.
- trueface: n -> ative após 20k + iterações.
- face_style_power: 10 -> para as primeiras 15k iterações. Depois desse ponto, defina-o como 0.
- bg_style_power: 10 -> Defina como 0 após 15k iterações. Os estilos consomem cerca de 30% mais VRAM.
- color_transfer: LCT / rct-pc produz os melhores resultados, mas recomendo tentar todos os estilos de transferência.
- clipgrad: n -> Isso pode supostamente evitar travamentos, então se o seu modelo entrar em colapso, ligue-o.
- batch_size: 8 -> Reduza se você estiver obtendo OOM (sem memória).
- sort_by_yaw: n -> Útil apenas quando você tem muito poucos source-faces.
- random_flip: y -> Dá mais variação ao material, realmente não pode machucar.

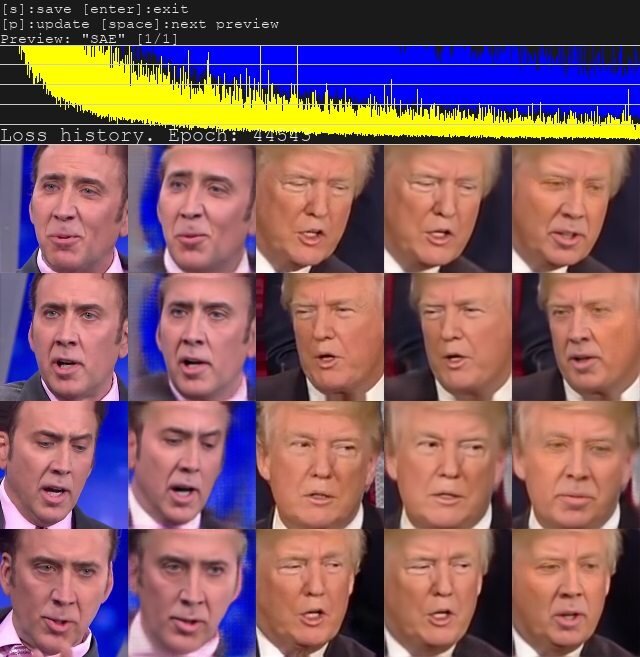
Agora, deixe correr enquanto você tiver paciência para esperar. Normalmente deixo o modelo treinar durante a noite, já que estou usando uma única GPU e não uma CPU ou GPU-farm. Você deve ter como objetivo pelo menos 20k iterações, mas qualquer coisa em torno da faixa de 100k iterações eu consideraria um modelo bastante decente. Ao olhar para a pré-visualização (veja as imagens acima), você deve conseguir distinguir os dentes e os olhos. Se eles não parecem estranhos, provavelmente você fez tudo certo. Caso contrário, verifique seu conjunto de dados e, em seguida, suas configurações de treinamento.
Mesclando os rostos
Finalmente, queremos fundir nossos dados de origem em nossos dados de destino. Faça isso, usaremos a fusão interativa – uma visualização que nos permite ajustar as configurações e ver os resultados imediatamente em uma imagem estática de nossa composição final. Para iniciar a conversão, basta executar:
“ 7) converter SAEHD.bat ”
E quando perguntado “interativo_converter” digite “y”. Isso abrirá uma janela intitulada “fusão”.
Você pode alternar entre o menu de atalho e a visualização pressionando tab. Vamos examinar cada configuração e tentarei o meu melhor para explicar o que cada opção faz.
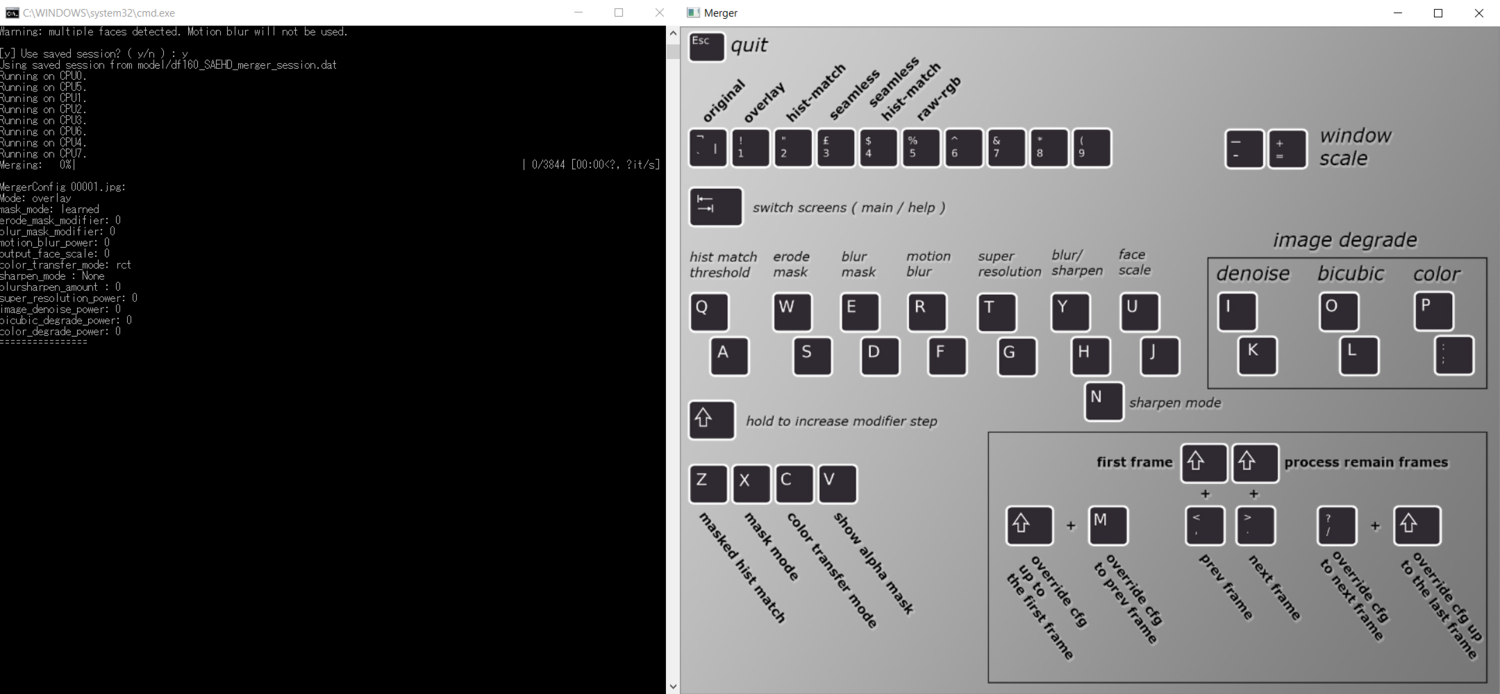
Vamos começar de cima para baixo. A linha de configurações no topo são os “ modos ”. Isso determina diretamente como os rostos serão colados em sua filmagem de destino. Você pode pressionar tab para alternar para a visualização e experimentar os diferentes modos, mas descobri que o único modo convincente era “sobreposição” em quase todos os casos.
A seguir, vamos dar uma olhada nas linhas do meio. Em primeiro lugar, temos o “ limite de correspondência hist ”. De acordo com este artigo que descobri, o limite de correspondência de hist determina quão precisa será aplicada a luz que é projetada sobre o rosto de nosso destino. No entanto, ao usar o modo “overlay”, você não será capaz de ajustar esta configuração, pois ela só funciona com “hist-match” e “seamless hist-match” de acordo com este guia (AVISO: o link leva a um possível Website NSWF)
- “ Erode Mask ” faz exatamente o que é dito. A erosão da máscara pode ajudar se o seu rosto treinado tiver algumas bordas feias ou artefatos digitais próximos à área externa do rosto.
- “ Máscara de desfoque ” pode ajudar a esconder a borda entre a filmagem original e o rosto falsos profundos, portanto, certifique-se de aumentar esse valor até que a borda seja menos visível.
- “ Motion Blur ” pode adicionar um pouco de realismo aplicando artificialmente o motion-blur no rosto profundo. Porém, isso leva muito mais tempo para converter, e se você tem conhecimento comum em After-Effects ou qualquer outro programa de composição como Nuke ou Fusion, você pode facilmente adicionar e ajustar o desfoque de movimento depois. Eu recomendo que você deixe esta configuração desativada.
- “ Super Resolução ” usa o RankSRGAN , outro GAN, para aprimorar e aprimorar as características do rosto. Isso pode ajudar especialmente nas áreas ao redor dos olhos. Não abuse dessa configuração, pois você aumentará a nitidez da imagem rapidamente. Aumente esta configuração até encontrar o rosto que pareça realista e – mais importante – que corresponda à nitidez do seu fundo.
- “ Blur / Sharpen ” oferece a opção de simplesmente desfocar ou aumentar a nitidez da imagem. Isso raramente é exigido pela minha experiência.
- “ Escala facial ” é outra opção importante, escalando a face para cima ou para baixo. Isso pode fazer ou quebrar seu deepfake, então reserve um tempo para ajustar a escala de maneira apropriada.
Agora chegamos à área do meio-direito, que nos dá opções para degradar a imagem. Essas configurações podem ajudar a degradar o rosto de pele profunda para que corresponda ao fundo, ou seja, a filmagem de destino. Brinque com as três opções até que seu rosto corresponda ao fundo. Se o seu vídeo de destino for de qualidade decente, essas configurações raramente são necessárias, por experiência própria.
Se dermos uma olhada nas opções do canto inferior esquerdo, podemos ver que esses atalhos correspondem às configurações da máscara. A máscara é simplesmente o canal alfa de nosso rosto, portanto, manipulá-la muda a forma como o rosto fica sobre a filmagem original.
- “ Correspondência hist mascarada ” não tem uso para o modo “sobreposição”.
- O “ modo de máscara ” permite que você escolha uma destas opções:
- dst: usa máscaras derivadas da forma dos pontos de referência gerados durante a extração do conjunto de dados / faces data_dst.
- learn-prd: usa máscaras aprendidas durante o treinamento. Mantenha a forma das faces de origem.
- learn-dst: usa máscaras aprendidas durante o treinamento. Mantenha a forma das faces de origem.
- learn-prd * dst: combina as duas máscaras, tamanho menor de ambas.
- learn-prd + dst: combina as duas máscaras, tamanho maior de ambas.
- XSeg-prd: usa o modelo XSeg treinado para mascarar usando dados de faces de origem.
- XSeg-dst: usa o modelo XSeg treinado para mascarar usando dados das faces de destino.
- XSeg-prd * dst: combina as duas máscaras, tamanho menor de ambas.
- learn-prd * dst * XSeg-dst * prd: combina todos os 4 modos de máscara, todos com tamanho menor.
- Experimente cada modo e veja qual se encaixa melhor na sua cena. Na minha experiência, “dst” funcionou bem na maioria dos casos.
- “ Modo de transferência de cor ” é outra configuração muito importante. Experimente os diferentes modos, pois o modo exigido difere de clipe para clipe. Na maioria das vezes, porém, “LCT” produziu bons resultados.
- “ Show alpha mask ” faz exatamente o que diz. Se você ligar e alternar para a visualização, poderá ver a área mascarada e até mesmo afetá-la com as outras configurações.
E isso foi para as configurações mais importantes e o que eles fazem. Agora, se você quiser, pode percorrer cada quadro usando os atalhos exibidos no canto inferior direito e ajustar as configurações de cada quadro, se necessário. Na maioria dos casos, porém, as configurações cabem para o clipe inteiro, uma vez ajustadas. Aqui está o que eu gosto de fazer para acelerar o processo.
Observe o console (prompt de comando) que foi aberto ao executar o script em lote. Lá, você encontrará todas as configurações que ajustou até agora. Faça uma captura de tela usando a ferramenta de recorte ou algo semelhante e feche o console e também a janela de visualização.
Em seguida, execute o script em lote novamente, mas escolha “n” quando solicitado pelo conversor interativo. Depois de fazer isso, você será solicitado a inserir as configurações desejadas. Basta colar as configurações de sua captura de tela no console. Você também será perguntado se deseja exportar uma máscara alfa . Digite “y” se quiser ajustar o rosto mais tarde, usando um programa de composição como o After-Effects ou Nuke.
Composição
Quase na linha de chegada! Nossa última etapa é compor o rosto no fundo e fazer os últimos ajustes em nosso software de composição. Esta etapa é opcional.
Depois de mesclar / converter todos os rostos, você terá uma pasta chamada “mesclado” dentro de sua pasta “data_dst” contendo todos os quadros que compõem o vídeo. Você também encontrará uma sequência png que conterá a máscara do seu rosto. A máscara será uma máscara de luminância branco sobre preto. Isso significa que quanto mais clara a área, mais opaca será a imagem. As áreas mais escuras (cinza) são mais transparentes e as áreas pretas são completamente transparentes.
Importe a sequência de imagens mescladas em seu programa de composição e também a sequência de imagens de máscara. Nos efeitos posteriores, você pode simplesmente usar o efeito “definir fosco” e escolher sua sequência de máscara como fosco, certificando-se de que lê a luminância como alfa. Agora você pode aplicar correção de cor ou outros ajustes a essa camada enquanto apenas afetando o rosto.
No final, tudo o que há a fazer é sobrepor a sequência “mesclada” não mascarada sob o rosto corrigido e mascarado e exportá-lo. Eu recomendo um h.264 .mp4 com uma taxa de bits de cerca de 5-10 para uploads regulares para o youtube. Se você planeja trabalhar com o arquivo e editá-lo mais tarde, recomendo exportar como um prores4444 .mov.
Conclusão
Para ser honesto, escrever este guia e pesquisar suas informações foi uma provação e tanto. O que se torna imediatamente aparente é a falta de pesquisas e informações concretas sobre os aspectos aprofundados relativos ao deepfaking.
Muitas das informações coletadas aqui se originam de reddit-posts, escassos artigos de pesquisa, dúbios sites NSWF e guias abaixo do ideal que fornecem informações conflitantes às vezes.
No final, tornou-se aparente que o processo de Deepfaking ainda não atingiu um nível de amizade com o consumidor e facilidade de uso para afirmar que “qualquer um poderia fazer um Deepfake”. Embora isso seja verdade no nível literal, espero que a maioria das pessoas esteja bastante sobrecarregada e sem o conhecimento necessário em um nível de TI para ter total confiança no que estão fazendo (isso também inclui eu, que só adquiri o conhecimento necessário para um Deepfake de sucesso depois de tentar e falhar muitas vezes.)
No entanto, será muito interessante observar o que o futuro reserva para os Deepfakes. Estou convencido de que, em algum ponto, a tecnologia se tornará avançada o suficiente e o uso de Deepfake-Algorithms fáceis de usar para que civis “normais” sejam capazes de criar Deepfakes em um curto espaço de tempo com uma pequena quantidade de trabalho manual.
Como tornar o Deepfakes mais fácil:
Na minha opinião, as partes mais difíceis do processo incluem a coleta de dados , bem como o uso de scripts em lote e console .
Para simplificar a coleta de dados, pode ser uma boa ideia usar um processo automatizado que envolva apenas inserir o nome de alguém e o algoritmo de busca de entrevistas ou vídeos que apresentem em destaque o rosto dessa pessoa, antes de capturar automaticamente o URL do vídeo, baixando o arquivo e dividindo os quadros em uma seqüência de imagens.
Para simplificar o manuseio dos scripts e etapas únicas, seria bom ter uma interface de usuário abrangente que todos pudessem usar, mesmo com pouca ou nenhuma afinidade técnica.
Eu acredito que Deepfakes tem um futuro intrigante com certeza. Desmascarar os Deepfakes e tentar criar Deepfakes inquestionáveis vai brincar de gato e rato como os programadores de software antivírus e vírus estão exibindo agora. Quando chegarmos ao ponto de substituir todo o corpo de alguém (sobre o qual já existem pesquisas convincentes), a evidência em vídeo sofrerá uma mudança tão drástica que prometo que todos falarão a respeito.
Obrigado por ler até o fim. Estas são as principais fontes de informação que usei para escrever este artigo:
Guia do Deepfakeblue para Deepfakes
Esta resposta de “planetoftheFakes” em um post no Reddit
A página Github do algoritmo DeepFaceLab de “iperov”
Este artigo no RankSRGAN para super-resolução
Este guia para Deepfakes (AVISO, NSFW!)