
Esta postagem vai falar sobre como ler documentos do Word com Python. Vamos cobrir três pacotes diferentes – docx2txt , docx e meu favorito pessoal: docx2python .
Indice
O pacote docx2txt
Vamos falar sobre docx2text primeiro. Este é um pacote Python que permite copiar texto e imagens de documentos do Word. O exemplo abaixo é lido em um documento do Word contendo o Zen do Python . Como você pode ver, depois de importar o docx2txt , tudo o que precisamos é de uma linha de código para ler o texto do documento do Word. Podemos ler o documento usando um método no pacote chamado processo , que leva o nome do arquivo como entrada. Texto normal, itens listados, texto de hiperlink e texto de tabela serão todos retornados em uma única string.
import docx2txt
# read in word file
result = docx2txt.process("zen_of_python.docx")

E se o arquivo tiver imagens? Nesse caso, precisamos apenas de um pequeno ajuste em nosso código. Quando executamos o método de processo , podemos passar um parâmetro extra que especifica o nome de um diretório de saída. A execução de docx2txt.process extrairá todas as imagens do documento do Word e as salvará nesta pasta especificada. O texto do arquivo também será extraído e armazenado na variável de resultado .
import docx2txt
result = docx2txt.process("zen_of_python_with_image.docx", "C:/path/to/store/files")Imagem de amostra

docx2txt também irá raspar qualquer texto das tabelas. Novamente, isso será retornado em uma única string com qualquer outro texto encontrado no documento, o que significa que esse texto pode ser mais difícil de analisar. Posteriormente neste post, falaremos sobre docx2python , que permite a você raspar tabelas em um formato mais estruturado.
O pacote docx
O código-fonte por trás do docx2txt é derivado do código no pacote docx , que também pode ser usado para copiar documentos do Word. docx é uma biblioteca poderosa para manipular e criar documentos do Word, mas também pode (com algumas restrições) ler texto de arquivos do Word.
No exemplo abaixo, abrimos uma conexão com nosso arquivo de palavras de amostra usando o método docx.Document . Aqui, apenas inserimos o nome do arquivo ao qual queremos nos conectar. Então, podemos raspar o texto de cada parágrafo no arquivo usando uma compreensão de lista em conjunto com doc.paragraphs . Isso incluirá a eliminação de linhas separadas definidas no documento do Word para os itens listados. Ao contrário do docx2txt , o docx não pode copiar imagens de documentos do Word. Além disso, o docx não raspará hiperlinks e texto em tabelas definidas no documento do Word.
import docx
# open connection to Word Document
doc = docx.Document("zen_of_python.docx")
# read in each paragraph in file
result = [p.text for p in doc.paragraphs]
O pacote docx2python
docx2python é outro pacote que podemos usar para copiar documentos do Word. Ele possui alguns recursos adicionais além de docx2txt e docx . Por exemplo, é capaz de retornar o texto extraído de um documento em um formato mais estruturado. Vamos testar nosso documento do Word com docx2python . Vamos adicionar uma tabela simples no documento para que possamos extraí-la também (veja abaixo).

docx2python contém um método com o mesmo nome. Se chamarmos este método com o nome do documento como entrada, obtemos de volta um objeto com vários atributos.
from docx2python import docx2python
# extract docx content
doc_result = docx2python('zen_of_python.docx')Cada atributo fornece texto ou informações do arquivo. Por exemplo, considere que nosso arquivo tem três componentes principais – o texto contendo o Zen do Python, uma mesa e uma imagem. Se chamarmos doc_result.body , cada um desses componentes será retornado como itens separados em uma lista .
# get separate components of the document
doc_result.body
# get the text from Zen of Python
doc_result[0]
# get the image
doc_result[1]
# get the table text
doc_result[2]Raspagem de uma tabela de documento do Word com docx2python
O resultado do texto da tabela é retornado como uma lista aninhada, como você pode ver abaixo. Cada linha (incluindo o cabeçalho) é retornada como uma sub-lista separada. O 0º elemento da lista refere-se ao cabeçalho – ou 0ª linha da tabela. O próximo elemento se refere à próxima linha na tabela e assim por diante. Por sua vez, cada valor em uma linha é retornado como uma sub-lista individual dentro da lista correspondente dessa linha.

Podemos converter este resultado em um formato tabular usando o pandas . O quadro de dados ainda está um pouco confuso – cada célula no quadro de dados é uma lista contendo um único valor. Este valor também tem alguns “\ t” ‘s (que representam espaços de tabulação).
pd.DataFrame(doc_result.body[1][1:])
Aqui, usamos o método applymap para aplicar a função lambda abaixo a cada célula no quadro de dados. Esta função obtém o valor individual dentro da lista em cada célula e remove todas as instâncias de “\ t”.
import pandas as pd
pd.DataFrame(doc_result.body[1][1:]).\
applymap(lambda val: val[0].strip("\t"))
A seguir, vamos alterar os cabeçalhos das colunas para o que vemos no arquivo do Word (que também foi retornado para nós em doc_result.body ).
df.columns = [val[0].strip("\t") for val in doc_result.body[1][0]]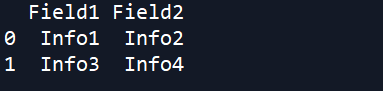
Extraindo imagens
Podemos extrair as imagens do arquivo Word usando o atributo images do nosso objeto doc_result . doc_result.images consiste em um dicionário onde as chaves são os nomes dos arquivos de imagem (não gravados automaticamente no disco) e os valores correspondentes são os arquivos de imagens em formato binário.
type(doc_result.images) # dict
doc_result.images.keys() # dict_keys(['image1.png'])Podemos gravar a imagem formatada em binário em um arquivo físico como este:
for key,val in doc_result.images.items():
f = open(key, "wb")
f.write(val)
f.close()Acima, estamos apenas fazendo um loop pelas chaves (nomes de arquivos de imagem) e valores (imagens binárias) no dicionário e escrevendo cada um para o arquivo. Nesse caso, temos apenas uma imagem no documento, então apenas escrevemos uma.
Outros atributos
O resultado docx2python tem vários outros atributos que podemos usar para extrair texto ou informações do arquivo. Por exemplo, se quisermos apenas obter todo o texto do arquivo em uma única string (semelhante a docx2txt ), podemos executar doc_result.text .
# get all text in a single string
doc_result.textAlém do texto, também podemos obter metadados sobre o arquivo usando o atributo properties . Isso retorna informações como o criador do documento, as datas de criação / última modificação e o número de revisões.
doc_result.propertiesSe o documento que você está copiando tem cabeçalhos e rodapés, você também pode raspar assim (observe a versão singular de “cabeçalho” e “rodapé”):
# get the headers
doc_result.header
# get the footers
doc_result.footerAs notas de rodapé também podem ser extraídas assim:
doc_result.footnotesObter HTML devolvido com docx2python
Também podemos especificar que queremos um objeto HTML retornado com o método docx2python que suporta alguns tipos de tags, incluindo fonte (tamanho e cor), itálico, negrito e texto sublinhado. Precisamos apenas especificar o parâmetro “html = True”. No exemplo abaixo, vemos O Zen do Python em negrito e sublinhado. Correspondendo a isso, podemos ver a versão HTML disso no segundo instantâneo abaixo. O recurso HTML atualmente não oferece suporte a tags relacionadas a tabelas, então eu recomendaria usar o método que vimos acima se você estiver procurando raspar tabelas de documentos do Word.
doc_html_result = docx2python('zen_of_python.docx', html = True)

Espero que tenha gostado deste post! Por favor, verifique outras postagens minhas sobre Python abaixo ou clicando aqui .