
Nesta postagem, veremos como você pode treinar o novo modelo YOLO v5 para reconhecer seus objetos personalizados para o seu caso de uso personalizado.

Cobriremos o seguinte material e você pode começar de qualquer lugar no processo de criação de seu modelo de detecção de objeto:
- Uma Visão Geral da Detecção de Objetos
- Sobre o modelo YOLO v5
- Coletando Nossas Imagens de Treinamento
- Anotando nossas imagens de treinamento
- Instale dependências YOLO v5
- Baixe dados de detecção de objetos YOLO v5 personalizados
- Definir a configuração e arquitetura do modelo YOLO v5
- Treine um detector YOLO v5 personalizado
- Avalie o desempenho do YOLO v5
- Execute a inferência YOLO v5 em imagens de teste
- Exportar pesos salvos do YOLO v5 para inferência futura
Recursos YOLOv5 neste tutorial
- Notebook Colab com código de treinamento YOLOv5 (eu recomendo que ele esteja aberto simultaneamente)
- Conjunto de dados de detecção de células sanguíneas públicas
Uma Visão Geral da Detecção de Objetos
A detecção de objetos é um dos modelos de visão computacional mais populares devido à sua versatilidade.
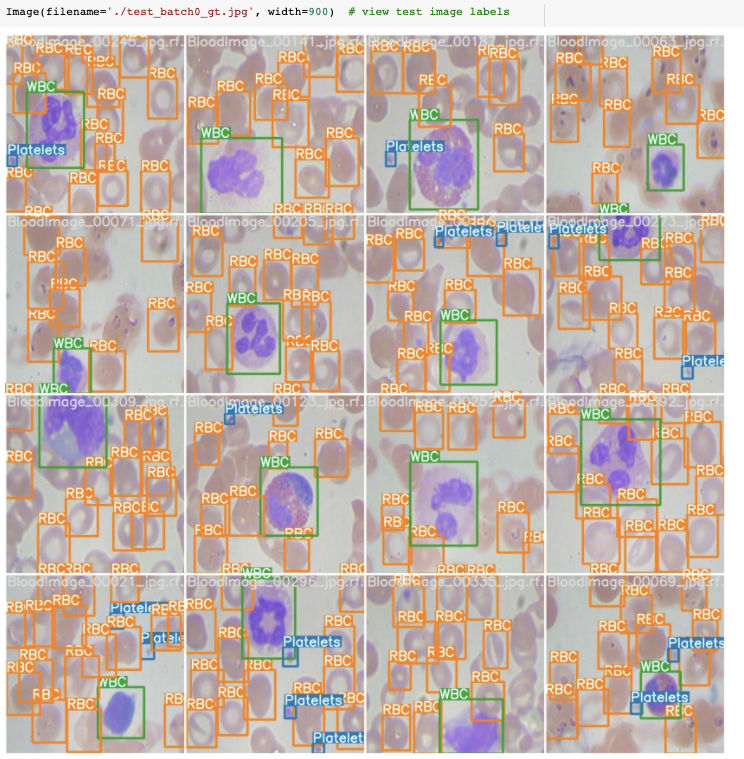
Os modelos de detecção de objetos procuram identificar a presença de objetos relevantes nas imagens e classificá-los em classes relevantes. Por exemplo, em imagens médicas, queremos ser capazes de contar o número de glóbulos vermelhos (RBC), glóbulos brancos (WBC) e plaquetas na corrente sanguínea. Para fazer isso automaticamente, precisamos treinar um modelo de detecção de objetos para reconhecer cada um desses objetos e classificá-los corretamente.
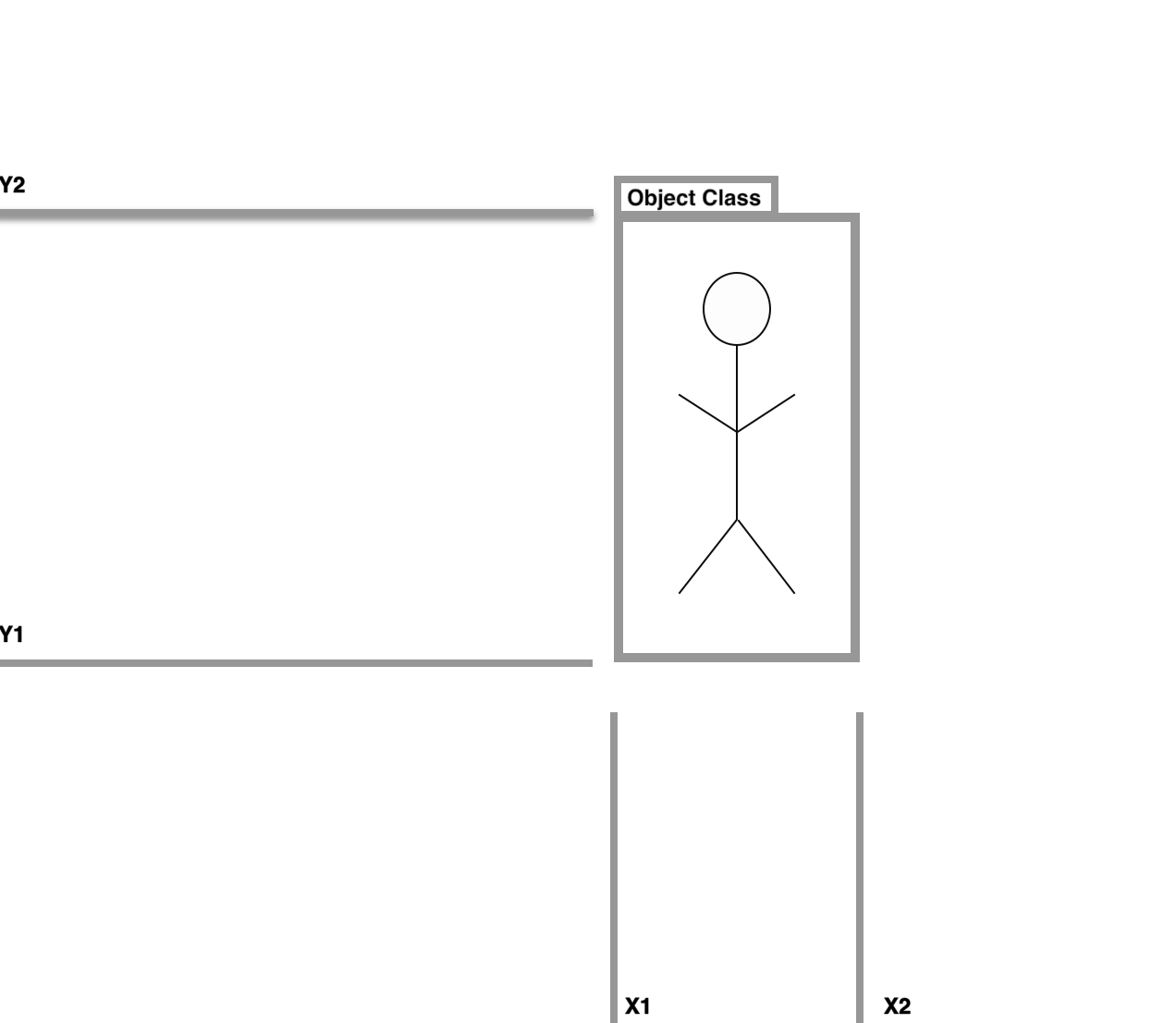
Nosso modelo de detector de objetos separará a regressão da caixa delimitadora das classificações de objetos em diferentes áreas de uma rede conectada.
Sobre o modelo YOLOv5
YOLOv5 é um lançamento recente de th e YOLO família de modelos. YOLO foi inicialmente apresentado como o primeiro modelo de detecção de objetos que combinava a previsão da caixa delimitadora e a classificação de objetos em uma única rede diferenciável ponta a ponta. Ele foi escrito e é mantido em uma estrutura chamada Darknet . YOLOv5 é o primeiro dos modelos YOLO a ser escrito na estrutura PyTorch e é muito mais leve e fácil de usar. Dito isso, o YOLOv5 não fez grandes mudanças arquitetônicas na rede no YOLOv4 e não supera o YOLOv4 em um benchmark comum, o conjunto de dados COCO.
Eu recomendo o YOLOv5 para você aqui porque acredito que é muito mais fácil começar e oferece muito mais velocidade de desenvolvimento ao passar para a implantação.
Coletando Nossas Imagens de Treinamento
Para tirar o detector de objetos do solo, primeiro você precisa coletar imagens de treinamento. Você deseja pensar cuidadosamente sobre a tarefa que está tentando realizar e pensar com antecedência sobre os aspectos da tarefa que seu modelo pode achar difícil. Eu recomendo restringir o domínio que seu modelo deve controlar tanto quanto possível para melhorar a precisão do seu modelo final.
No caso deste tutorial, limitamos o escopo de nosso detector de objetos para detectar apenas células na corrente sanguínea . Este é um domínio estreito que pode ser obtido com as tecnologias atuais.
Para começar, recomendo:
- restringir sua tarefa para identificar apenas 10 ou menos classes e coletar de 50 a 100 imagens .
- tente certificar-se de que o número de objetos em cada classe seja distribuído uniformemente.
- escolha objetos que sejam distinguíveis. Um conjunto de dados composto principalmente de carros e apenas alguns jipes, por exemplo, será difícil para o seu modelo dominar.
E, claro, se você quer apenas aprender a nova tecnologia, pode escolher vários conjuntos de dados de detecção de objetos gratuitos . Escolha BCCD se quiser seguir diretamente no tutorial.
Anotando nossas imagens de treinamento
Para treinar nosso detector de objetos, precisamos supervisionar seu aprendizado com anotações de caixa delimitadora. Desenhamos uma caixa ao redor de cada objeto que queremos que o detector veja e rotulamos cada caixa com a classe de objeto que gostaríamos que o detector previsse.
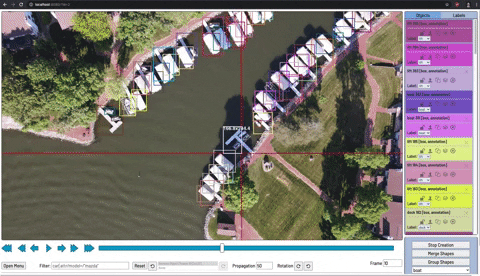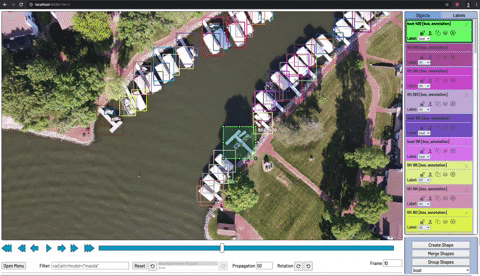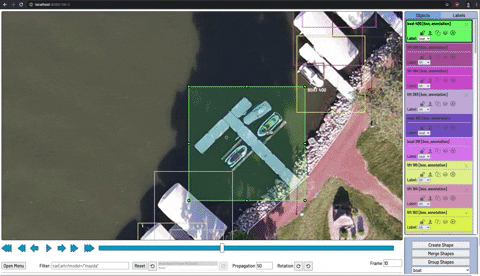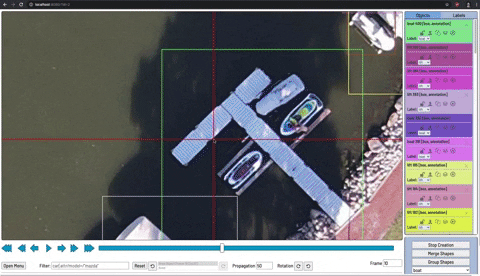
Existem muitas ferramentas de etiquetagem ( CVAT , LabelImg , VoTT ) e soluções em grande escala (Scale, AWS Ground Truth,. Para começar a usar uma ferramenta de etiquetagem gratuita.
Ao desenhar suas caixas encadernadas, certifique-se de seguir as práticas recomendadas:
- Etiqueta em toda a volta do objeto em questão
- Rotular objetos obstruídos inteiramente
- Evite muito espaço ao redor do objeto em questão
OK! Agora que preparamos um conjunto de dados, estamos prontos para entrar no código de treinamento YOLOv5. Segure seu conjunto de dados, iremos importá-lo em breve.
Abra simultaneamente : Notebook Colab para treinar YOLOv5 .
No Google Colab, você receberá uma GPU gratuita. Certifique-se de Arquivo → salvar uma cópia em sua unidade. Então você poderá editar o código.
Instalando o ambiente YOLOv5
Para começar com o YOLOv5, primeiro clonamos o repositório YOLOv5 e instalamos as dependências. Isso configurará nosso ambiente de programação para estar pronto para executar o treinamento de detecção de objetos e comandos de inferência.
! git clone https://github.com/ultralytics/yolov5 # clone repo ! pip install -U -r yolov5 / requirements.txt # instale dependências% cd / content / yolov5
Então, podemos dar uma olhada em nosso ambiente de treinamento fornecido gratuitamente pelo Google Colab.
import torch
from IPython.display import Image # para exibir imagens
de utils.google_utils import gdrive_download # para baixar models / datasetsprint ('torch% s% s'% (torch .__ version__, torch.cuda.get_device_properties (0) se torch.cuda.is_available () else 'CPU'))
É provável que você receba uma GPU Tesla P100 do Google Colab. Aqui está o que recebi:
tocha 1.5.0 + cu101 _CudaDeviceProperties (name = 'Tesla P100-PCIE-16GB', major = 6, minor = 0, total_memory = 16280 MB, multi_processor_count = 56)
A GPU nos permitirá acelerar o tempo de treinamento. O Colab também é bom porque vem pré-instalado com torche cuda. Se você estiver tentando este tutorial no local, pode haver etapas adicionais a serem executadas para configurar o YOLOv5.
Baixar dados de detecção de objetos YOLOv5 personalizados
Neste tutorial, faremos download dos dados de detecção de objetos personalizados no formato YOLOv5 do Roboflow . Você pode acompanhar o conjunto de dados de células sanguíneas públicas ou carregar seu próprio conjunto de dados.
Depois de rotular os dados, para mover seus dados para o Roboflow, crie uma conta gratuita e, em seguida, você pode arrastar seu conjunto de dados em qualquer formato: ( VOC XML , COCO JSON , TensorFlow Object Detection CSV, etc).
Após o upload, você pode escolher as etapas de pré-processamento e aumento:
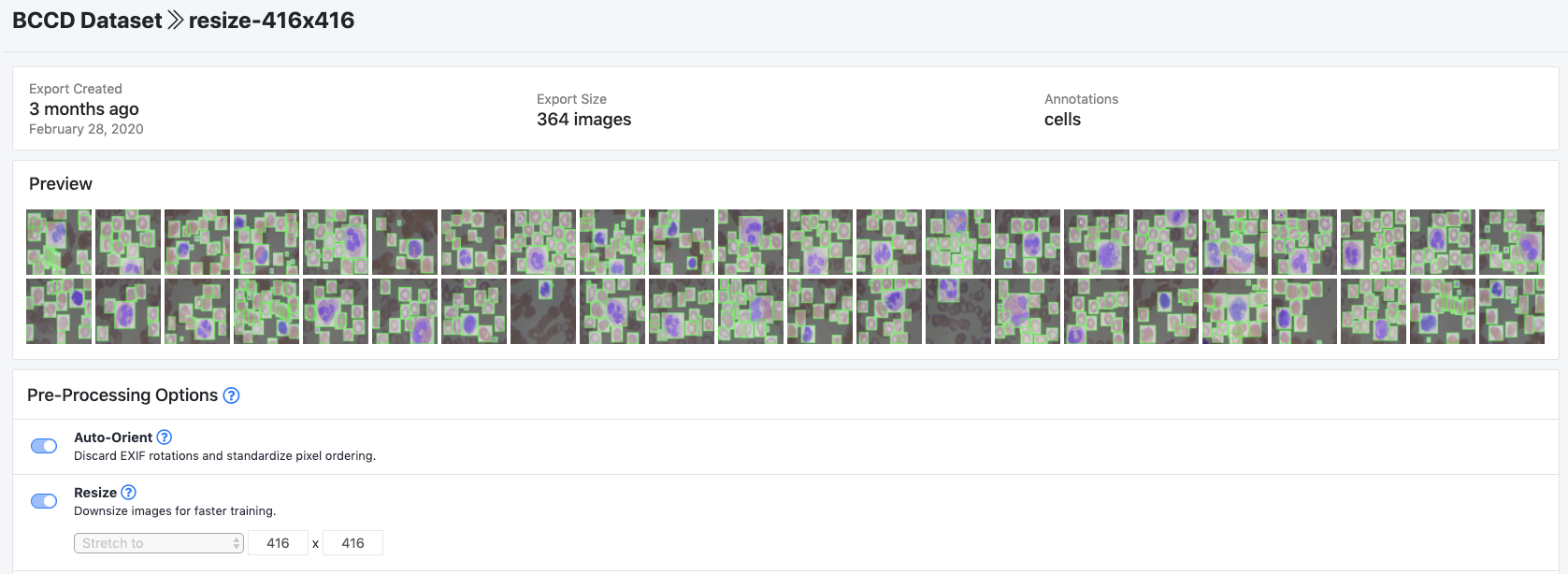
Em seguida, clique em Generatee Downloade você poderá escolher o formato YOLOv5 PyTorch.
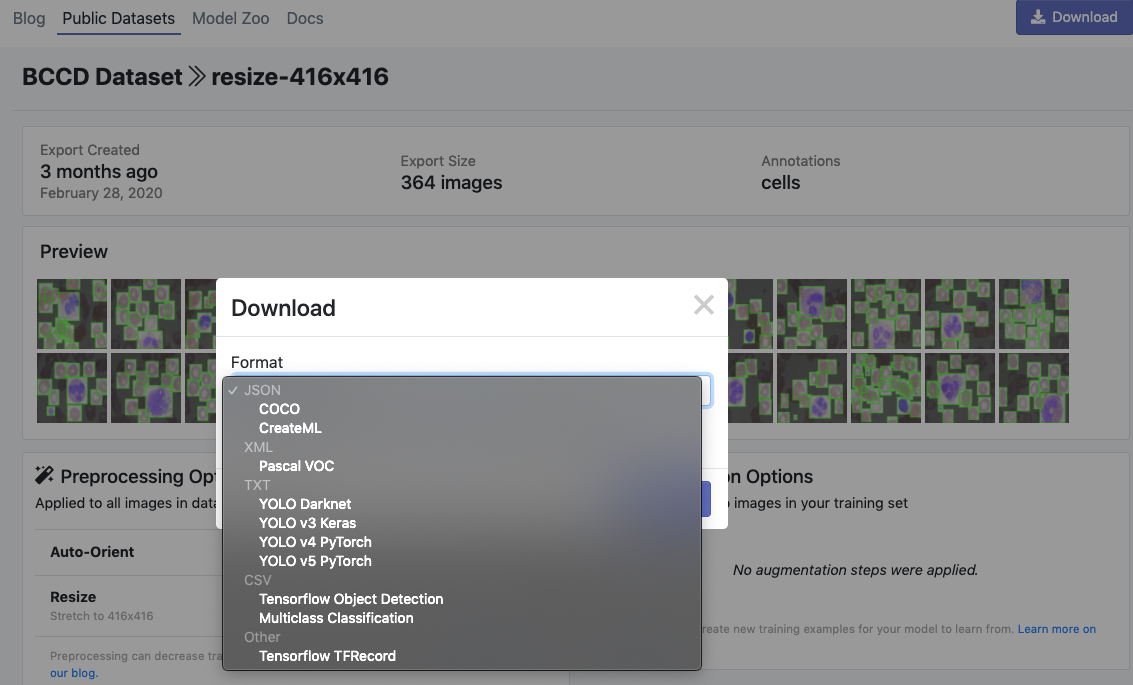
Quando solicitado, certifique-se de selecionar “Mostrar trecho de código”. Isso gerará um script de download curl para que você possa facilmente transportar seus dados para o Colab no formato adequado.
curl -L " https://public.roboflow.ai/ds/YOUR-LINK-HERE "> roboflow.zip; descompacte roboflow.zip; rm roboflow.zip
Baixando no Colab…
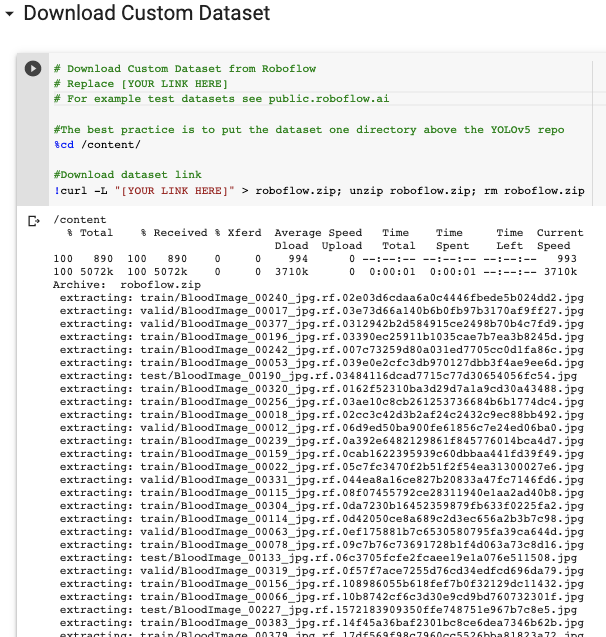
A exportação cria um arquivo YOLOv5 .yaml chamado data.yamlespecificando a localização de uma imagespasta YOLOv5 , uma labelspasta YOLOv5 e informações sobre nossas classes personalizadas.
Definir a configuração e arquitetura do modelo YOLOv5
Em seguida, escrevemos um arquivo de configuração de modelo para nosso detector de objetos personalizados. Para este tutorial, escolhemos o menor e mais rápido modelo básico de YOLOv5. Você tem a opção de escolher entre outros modelos YOLOv5, incluindo:
- YOLOv5s
- YOLOv5m
- YOLOv5l
- YOLOv5x
Você também pode editar a estrutura da rede nesta etapa, embora raramente seja necessário fazer isso. Aqui está o arquivo de configuração do modelo YOLOv5, que denominamos custom_yolov5s.yaml:
nc: 3
profundidade_múltiplo: 0,33
largura_múltiplo: 0,50âncoras:
- [10,13, 16,30, 33,23]
- [30,61, 62,45, 59,119]
- [116,90, 156,198, 373,326]backbone:
[[-1, 1, Foco, [64, 3]],
[-1, 1, Conv, [128, 3, 2]],
[-1, 3, Gargalo, [128]],
[- 1, 1, Conv, [256, 3, 2]],
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]],
[-1, 9 , BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]],
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 6, BottleneckCSP, [1024]],
]head:
[[-1, 3, BottleneckCSP, [1024, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]],
[-2, 1 , nn.Upsample, [None, 2, "mais próximo"]],
[[-1, 6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 3, BottleneckCSP, [512, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]],
[-2, 1, nn. Upsample, [Nenhum, 2, "mais próximo"]],
[[-1, 4], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]],
[-1 , 3, BottleneckCSP, [256, False]],
[-1, 1, nn.Conv2d, [na * (nc + 5), 1, 1, 0]],[[], 1, Detectar, [nc, âncoras]],
]
Detector de treinamento YOLOv5 personalizado
Com os nossos data.yamle custom_yolov5s.yamlarquivos prontos para ir, estamos prontos para treinar!
Para iniciar o treinamento, executamos o comando de treinamento com as seguintes opções:
- img: define o tamanho da imagem de entrada
- lote: determinar o tamanho do lote
- épocas: defina o número de épocas de treinamento. (Observação: geralmente, mais de 3.000 são comuns aqui!)
- dados: defina o caminho para nosso arquivo yaml
- cfg: especifique a configuração do nosso modelo
- pesos: especifique um caminho personalizado para os pesos. (Observação: você pode baixar pesos da pasta Ultralytics Google Drive )
- nome: nomes dos resultados
- nosave: salvar apenas o ponto de verificação final
- cache: imagens de cache para treinamento mais rápido
E execute o comando de treinamento:
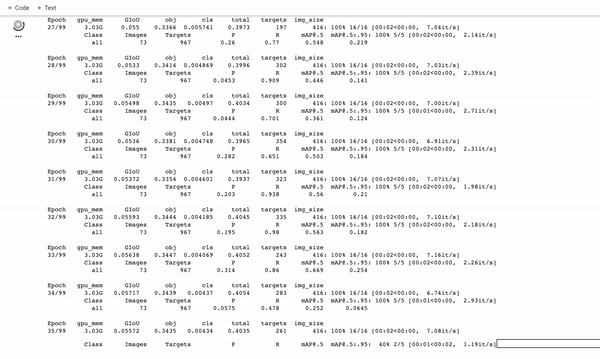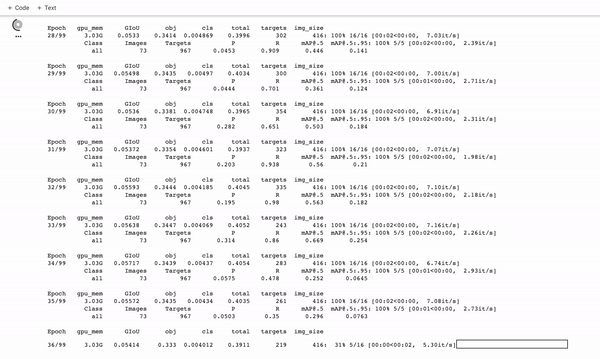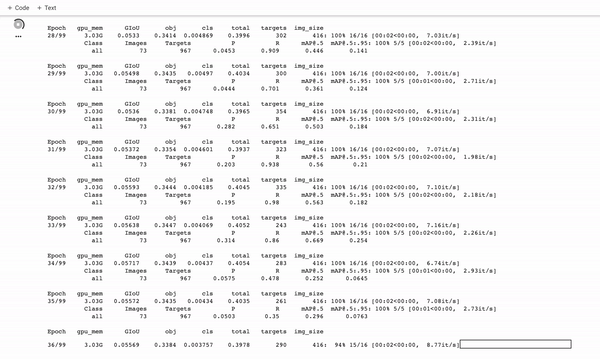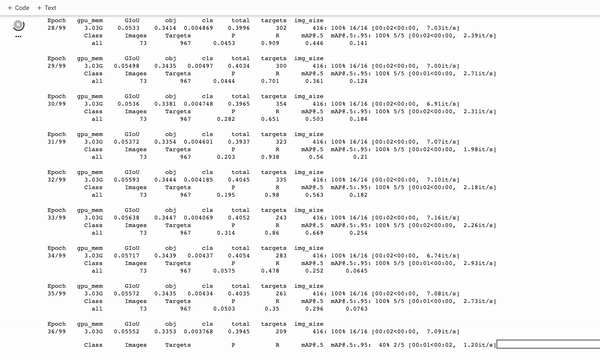
Durante o treinamento, você deseja observar o mAP@0.5 para ver como seu detector está aprendendo a detectar em seu conjunto de validação, quanto mais alto, melhor! – veja este post sobre como quebrar o mAP .
Avalie o desempenho do detector YOLOv5 personalizado
Agora que concluímos o treinamento, podemos avaliar quão bem o procedimento de treinamento foi executado, observando as métricas de validação. O script de treinamento irá inserir os registros do tensorboard runs. Nós os visualizamos aqui:
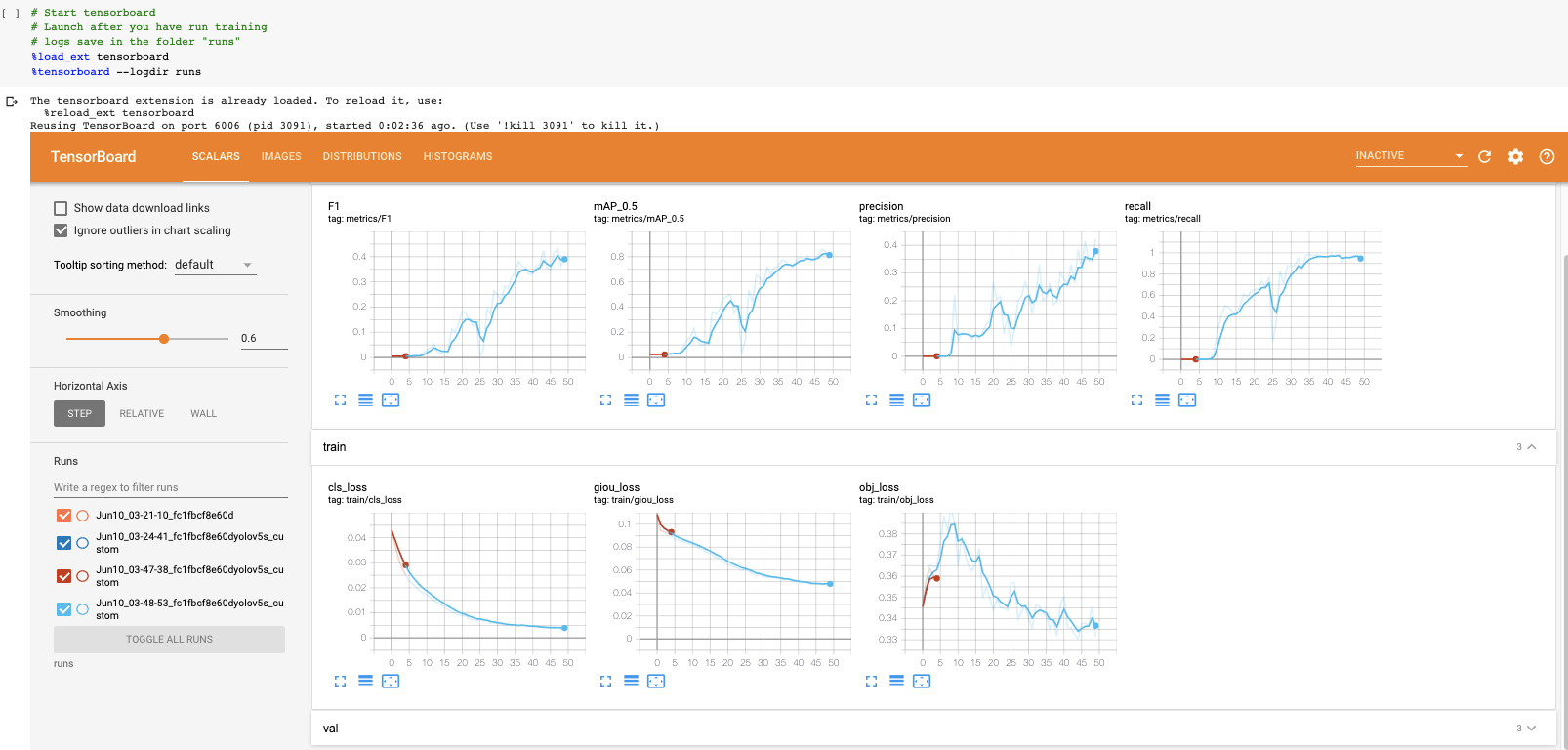
E se você não puder visualizar o Tensorboard por qualquer motivo, os resultados também podem ser plotados utils.plot_resultse salvando um result.png.
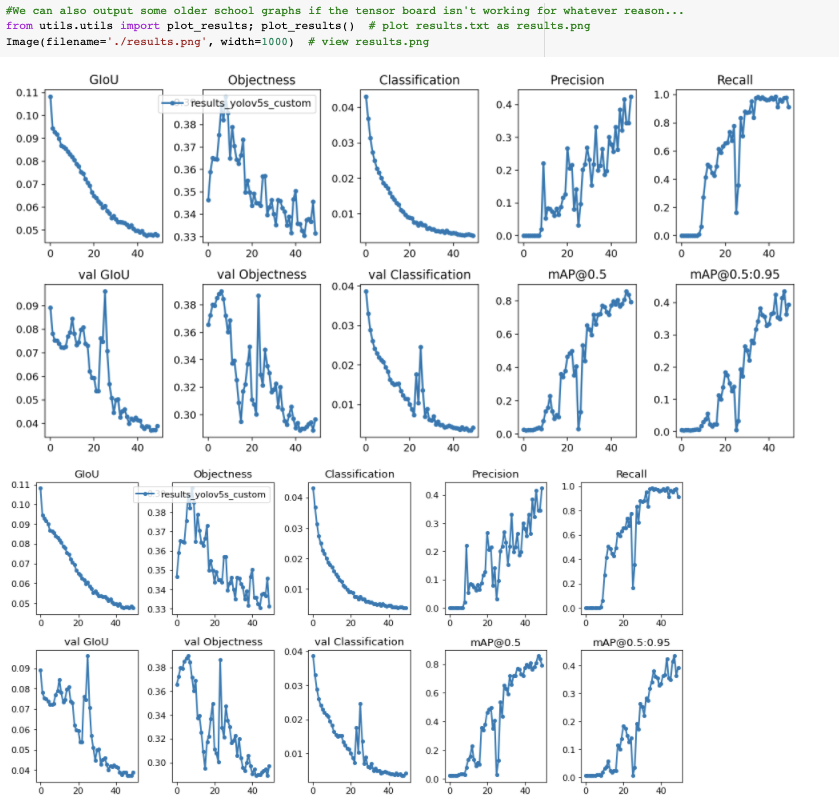
Parei de treinar um pouco cedo aqui. Você deseja obter os pesos do modelo treinado no ponto em que o mAP de validação atinge seu ponto mais alto.
Execute a inferência YOLOv5 em imagens de teste
Agora pegamos nosso modelo treinado e fazemos inferências nas imagens de teste. Após a conclusão do treinamento, os pesos do modelo economizarão em weights/. Para inferência, invocamos esses pesos junto com uma confconfiança do modelo de especificação (uma confiança mais alta necessária faz menos previsões) e uma inferência source. sourcepode aceitar um diretório de imagens, imagens individuais, arquivos de vídeo e também uma porta de webcam do dispositivo . Como fonte, mudei nosso test/*jpgpara test_infer/.
! python detect.py --weights weight / last_yolov5s_custom.pt --img 416 --conf 0.4 --source ../test_infer
O tempo de inferência é extremamente rápido. Em nosso Tesla P100, o YOLOv5s está atingindo 7ms por imagem. Isso é um bom presságio para a implantação em uma GPU menor como um Jetson Nano (que custa apenas US $ 100).
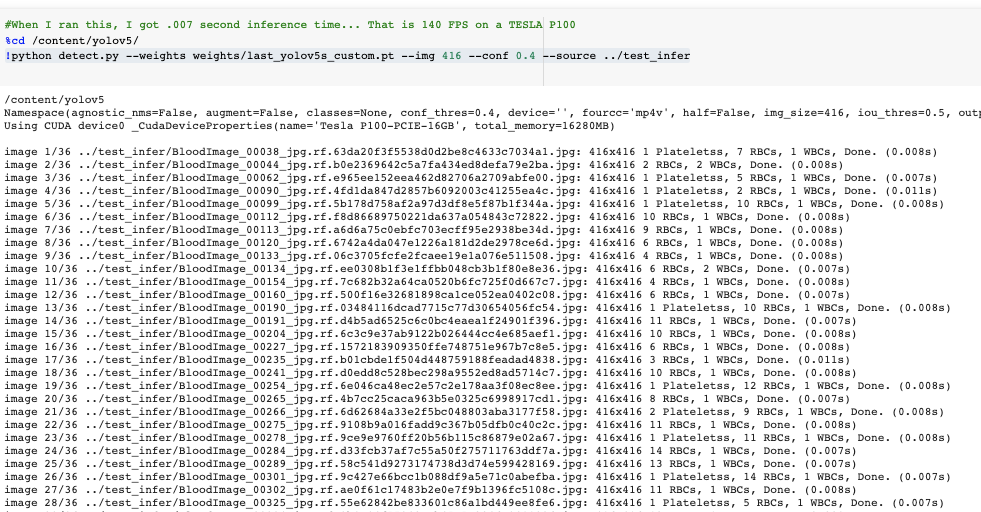
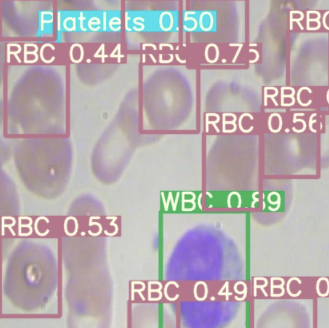
Por fim, visualizamos as inferências de nossos detectores nas imagens de teste.
Exportar pesos YOLOv5 salvos para inferência futura
Agora que nosso detector de objetos YOLOv5 personalizado foi verificado, podemos tirar os pesos do Colab para usar em uma tarefa de visão por computador ao vivo. Para isso, importamos um módulo do Google Drive e os enviamos.
de google.colab import drive
drive.mount ('/ content / gdrive')% cp /content/yolov5/weights/last_yolov5s_custom.pt / content / gdrive / My \ Drive
Conclusão
Esperamos que você tenha gostado de treinar seu detector de objetos YOLO v5 personalizado !
YOLO v5 é leve e extremamente fácil de usar. O YOLO v5 treina rapidamente, faz inferências rapidamente e tem um bom desempenho.
Vamos colocar isso para fora!
Próximas etapas: fique atento para tutoriais futuros e como implantar seu novo modelo para produção.