
Cobrindo todos os conceitos básicos e elementares do Python necessários para iniciar o Data Science com exemplos de código
Python para ciência de dados para 2022 – Python é uma das linguagens de programação mais importantes da era moderna. Embora a linguagem tenha sido desenvolvida há quase três décadas, há tanto em constante evolução que ainda possui imenso valor e muito mais a oferecer, especialmente em termos de Ciência de Dados e Inteligência Artificial.
A versão atual do Python 3.10 evoluiu da era anterior do Python 2, e o crescimento dessa linguagem de programação, bem como de sua comunidade, está em alta.
Com a imensa popularidade alcançada em Data Science e Inteligência Artificial devido aos consistentes desenvolvimentos e avanços nessas tecnologias, há uma grande curiosidade para ver até onde esses tremendos assuntos vão voar, especialmente com Python como a principal linguagem de desenvolvimento para eles.
Viveremos uma nova era, pois temos mais entusiastas que estão constantemente absorvendo a maioria desses conceitos modernos e contribuindo imensamente para a progressão desses campos. Com o próximo ano se aproximando rapidamente, muitos de nós temos novas metas para aprender novos tópicos intrigantes e progredir ainda mais.
Neste artigo, nosso foco principal é estabelecer uma compreensão básica de todos os conceitos essenciais que são úteis para a Ciência de Dados e obter uma compreensão primária de como podemos utilizar o Python nos tornando mais proficientes nas áreas de Inteligência Artificial, Aprendizado de Máquina e Ciência de Dados. .
Vamos nos concentrar em tópicos específicos que os desenvolvedores devem focar principalmente para alcançar os melhores resultados enquanto trabalham em projetos de Data Science.
Declarações Iterativas:
Depois de obter uma breve compreensão do significado da programação orientada a objetos com Python, vamos explorar o conceito de instruções iterativas em Python. A maioria das linguagens de programação, como Java e C++, geralmente faz uso de algumas instruções iterativas, como loop for, loop while, instruções do-while, switch case e outras iterações semelhantes.
Em Python, na maioria das vezes utilizamos apenas o loop For ou o loop While efetivamente. A maioria dos cálculos são realizados com essas duas instruções iterativas. Com a ajuda da programação Python, você pode executar esses loops iterativos desde que uma determinada condição seja satisfeita (ou seja, True). Assim, torna-se fácil executar um determinado bloco de código até que o propósito requerido seja continuamente satisfeito.
Seja ciência de dados ou programação simples em Python, instruções iterativas são consideradas obrigatórias. Quase todos os projetos de qualquer assunto utilizam esses loops repetidos para a execução de uma tarefa específica. A maioria dos meus projetos dos meus artigos anteriores também faz uso dessas declarações. Um dos melhores exemplos a seguir é de um dos meus blogs anteriores para criar um testador de palavrões de linguagem.
sentence = "You are not only stupid , but also an idiot ."
def censor(sentence = ""):
new_sentence = ""
for word in sentence.split():
if word in Banned_List:
new_sentence += '* '
else:
new_sentence += word + ' '
return new_sentenceOOPs:
Python é uma linguagem de programação orientada a objetos e é um dos aspectos mais essenciais do Python. No entanto, esse recurso às vezes é negligenciado por causa de outros recursos incríveis do Python. Portanto, este tópico deve ser nosso foco principal para começar a usar o Python for Data Science. Ao trabalhar com vários aspectos do Python, às vezes é possível esquecer o significado da programação orientada a objetos.
Cada biblioteca para aprendizado de máquina, ciência de dados ou qualquer estrutura de aprendizado profundo em Python constituirá principalmente dois componentes primários essenciais, ou seja, objetos e classes. Entidades do mundo real como classes, encapsulamento, polimorfismo e herança também são implementadas muito bem em Python. Portanto, nosso objetivo é entender todos os conceitos em detalhes extremos, e exploraremos esses conceitos em profundidade no próximo artigo.
Abaixo está um código de início rápido para começar com as classes.
class Derivative_Calculator:
def power_rule(*args):
deriv = sympy.diff(*args)
return deriv
def sum_rule(*args):
derive = sympy.diff(*args)
return derivdifferentiatie = Derivative_Calculator
differentiatie.power_rule(Derivative)Listas:
Uma lista é uma sequência ordenada mutável de elementos. Mutável significa que a lista pode ser modificada ou alterada. As listas são colocadas entre colchetes ‘[ ]’. Listas são um tipo de estrutura de dados sequenciada com cada elemento da lista sendo atribuído a um número de índice específico pelo qual ele pode ser acessado. Cada item ou elemento em uma lista é separado por uma vírgula (,).
lst = ['one', 'two', 'three', 'four']
lst.append('five')
lstSaída:
['one', 'two', 'three', 'four', 'five']As funções de acréscimo são um dos comandos mais significativos utilizados no mundo da programação e da ciência de dados. Existem várias outras funções que podemos realizar e manipular em listas.
Dicionários:
Os dicionários permitem que os usuários acessem chaves e valores de acordo. Digamos que você tenha que armazenar alguns dados de uma pessoa, então os dicionários são algo que você consideraria usar, como armazenar um nome de contato junto com seu número. Os dicionários também podem armazenar vários elementos de dados associados ao particular. Um nome específico de um aluno em uma escola pode ter marcas de várias disciplinas armazenadas. Dicionários são estruturas de dados em Python que são definidas como uma coleção não ordenada de dados. Abaixo estão alguns exemplos de código e saída para começar com os dicionários.
# Return a list of tuples of the dictionary items in the (key, value) form
my_dict = {1: 'A', 2: 'B', 3: 'C'}
print(my_dict.items())
# Return a new view of the dictionary keys
my_dict = {1: 'A', 2: 'B', 3: 'C'}
print(my_dict.keys())
# Return a new view of the dictionary values
my_dict = {1: 'A', 2: 'B', 3: 'C'}
print(my_dict.values())Saída:
dict_items([(1, 'A'), (2, 'B'), (3, 'C')])
dict_keys([1, 2, 3])
dict_values(['A', 'B', 'C'])O código inicial acima deve permitir que os usuários obtenham uma breve compreensão de alguns dos conceitos elementares de como usar valores de dicionário e elementos-chave.
Funções:
As funções permitem que os usuários manipulem rapidamente tarefas repetíveis dentro de um bloco de código sob o comando def function name():. Esse conceito é extremamente útil em programação, especialmente ciência de dados, onde você precisará repetir ações específicas em grandes conjuntos de dados. A utilização de uma função para atingir esse objetivo reduzirá a grande quantidade de cálculos que o desenvolvedor precisará realizar.
O Python também permite que seus usuários acessem diretamente algumas de suas opções de funções anônimas (ou avançadas) que ajudarão a desenvolver seus projetos mais rapidamente com maior eficiência. Eu já abordei o seguinte tópico com imensos detalhes em outro artigo, e eu recomendaria dar uma olhada se você estiver interessado em explorar mais esse tópico.
Explorando bibliotecas Python para ciência de dados:
A melhor característica do Python é o enorme número de bibliotecas disponíveis para essa linguagem de programação. Para quase todo tipo de tarefa que você deseja realizar ou qualquer tipo de projeto em que deseja trabalhar, o Python oferece uma biblioteca que simplificará ou reduzirá o trabalho em uma quantidade enorme.
Com a ajuda de algumas das melhores bibliotecas de Data Science oferecidas pelo Python, você pode concluir qualquer tipo de tarefa que pretenda realizar. Vamos explorar algumas das bibliotecas obrigatórias para iniciantes em Data Science.
1. Pandas:
Para trabalhar com ciência de dados, um dos principais requisitos é analisar os dados. Uma das melhores bibliotecas que Python oferece a seus usuários é a biblioteca Pandas, por meio da qual você pode acessar a maior parte do conteúdo que está disponível na internet em formato estruturado. Ele oferece aos desenvolvedores a opção de acessar vários arquivos em vários formatos, como texto, HTML, CSV, XML, látex e muito mais. Abaixo está um dos exemplos com os quais você pode acessar os dados do tipo formato CSV.
data = pd.read_csv("fer2013.csv")
data.head()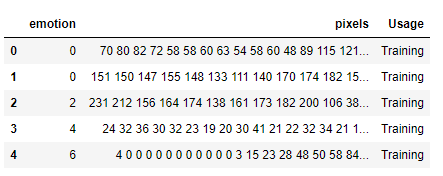
Para entender mais sobre o Pandas e conquistar o utilitário de análise por trás dessa biblioteca, recomendo verificar um dos meus artigos anteriores sobre as quatorze operações Pandas mais essenciais que devem ser incluídas no arsenal de todo cientista de dados. Abaixo segue o link para o mesmo.14 operações de pandas que todo cientista de dados deve conhecer!Guia completo sobre quatorze das operações Pandas mais essenciaisparadatascience.com
2. Matplotlib:
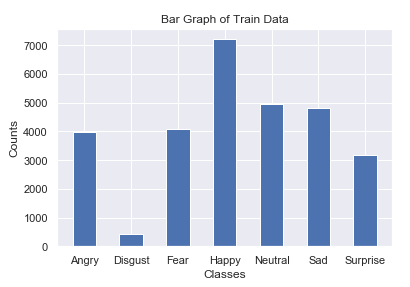
Depois de terminar de analisar seus dados, o próximo passo essencial é visualizá-los de acordo. Para a visualização de dados, o matplotlib junto com o seaborn é uma das melhores opções disponíveis em Python. Você pode visualizar quase qualquer entidade essencial com esta fantástica biblioteca com códigos simplistas. Ele suporta extensões numéricas como NumPy, que você pode combinar para visualizar a maioria dos elementos de dados.
A representação da imagem acima mostra um gráfico de barras construído com a ajuda da biblioteca matplotlib. Existem várias outras visualizações, gráficos e outros visuais estatísticos que podemos realizar com o matplotlib.
3. NumPy:
Numerical Python ou NumPy, em suma, é uma das melhores opções disponíveis em Python para o cálculo de problemas matemáticos. Você pode utilizar o conceito de matrizes numpy para simplificar a matemática complexa envolvida no campo da ciência de dados. Ele ajuda você a lidar com matrizes e matrizes grandes e multidimensionais e na construção eficiente de seus projetos de ciência de dados.
Sem a utilidade adequada do numpy, torna-se quase impossível resolver a maioria dos problemas matemáticos complexos e projetos de aprendizado de máquina. Por isso, é essencial compreender este conceito em grande detalhe.
4. Aprendizado do Scikit:
O Scikit-learn é uma das melhores bibliotecas com as quais você pode implementar todos os algoritmos essenciais de aprendizado de máquina, como classificação, regressão, clustering, pré-processamento (como mostrado no código abaixo), seleção de modelo, redução de dimensionalidade e muito mais. O kit de ferramentas da biblioteca faz uso de ferramentas simplistas, mas altamente eficientes para a análise e computação de dados. Não é apenas simples de instalar como os outros três módulos mencionados anteriormente, mas também é construído em cima desses pacotes cruciais como matplotlib, numpy e scipy. Para iniciantes, essa ferramenta de código aberto é um aprendizado obrigatório para implementar projetos de aprendizado de máquina com mais eficiência.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(questions, response, test_size=0.20)5. NLTK:
O kit de ferramentas de linguagem natural é uma das melhores bibliotecas para lidar com dados de linguagem humana. No início, a maioria dos projetos de aprendizado de máquina e ciência de dados lidará com muitas tarefas de processamento de linguagens naturais. A limpeza de seus dados é uma das etapas mais essenciais exigidas no estágio de preparação de dados para a maioria dos problemas relacionados ao processamento de linguagem natural. Portanto, essa biblioteca é extremamente crítica para aprender e se acostumar se você estiver começando no campo.
import nltk
sentence = "Hello! Good morning."
tokens = nltk.word_tokenize(sentence)Conclusão:
“Código é como humor. Quando você tem que explicar, é ruim.” – Casa Cory
Python é uma linguagem de programação revolucionária, pois conseguiu se manter relevante ao longo das décadas devido à sua simplicidade, facilidade de aprendizado, versatilidade e muitos outros recursos fabulosos. Com o surgimento da Inteligência Artificial e da Ciência de Dados nos últimos anos, o Python criou uma enorme reputação por ser uma das linguagens dominantes nesses campos e algo que todos devem procurar entender eventualmente.
Neste artigo, abordamos a maioria dos conceitos essenciais para começar a usar o Python para se tornar mais proficiente em Data Science. Nós nos concentramos na maioria dos tópicos elementares em Python que encontram enorme utilidade na maioria das áreas da Ciência de Dados e serão úteis para a conclusão bem-sucedida da maioria dos projetos. Se você conseguir dominar todas as metodologias mencionadas neste artigo, poderá navegar pela maioria dos projetos básicos de Data Science com facilidade.
Se você tiver alguma dúvida relacionada aos vários pontos mencionados neste artigo, sinta-se à vontade para me informar nos comentários abaixo. Vou tentar voltar para você com uma resposta o mais rápido possível.
Confira alguns dos meus outros artigos em relação ao tema abordado nesta peça que você também pode gostar de ler!
Créditos: towardsdatascience