
Projetos de engenharia de dados o “Portfólios são tudo, promessas não são nada. Coloque a mão na massa.” ~ Chase Jarvis
“Engenharia de Dados”
Você pode ter ouvido falar sobre isso.
Hmmm…O que é essa nova área? Você pode saber sobre ciência de dados e aprendizado de máquina, mas o que é engenharia de dados? É uma tecnologia nova ou algo que sempre fez parte da tecnologia?
Você foi mordido pelo bichinho da curiosidade. Você quer aprender sobre isso e gostaria de sujar as mãos, aprendendo.
Ou você já sabe sobre engenharia de dados e gostaria de mostrar suas habilidades, talvez para um empregador em potencial ou apenas para saciar seu apetite. Ou por qualquer outro motivo.
Trabalhar em um projeto é a melhor maneira de aprender, e construir um projeto de portfólio é uma boa maneira de mostrar suas novas habilidades.
Um projeto de portfólio ou um projeto de conclusão é um projeto bem pensado e projetado que mostra suas habilidades para um empregador em potencial ou para o mundo.
Observação: A engenharia de dados sempre fez parte do setor de TI. Mas com Big Data, esta é agora uma unidade diferente do setor de TI devido à quantidade de carga de trabalho e às habilidades necessárias para lidar com grandes quantidades de dados.
Vou começar definindo “ Engenharia de Dados ”, conforme definido por precisamentemim.com.br:
A engenharia de dados é a tarefa complexa de tornar os dados brutos utilizáveis para cientistas de dados e grupos dentro de uma organização. A engenharia de dados abrange várias especialidades da ciência de dados.
Além de tornar os dados acessíveis, os engenheiros de dados criam análises de dados brutos para fornecer modelos preditivos e mostrar tendências de curto e longo prazo. Sem engenharia de dados, seria impossível entender a enorme quantidade de dados que estão disponíveis para as empresas.
Passos para guiar
Ao criar um projeto de portfólio, aqui estão as etapas para ajudar a guiá-lo pelo projeto:
1. Escopo do projeto
Aqui definimos os objetivos; a motivação do negócio para o projeto. Vamos usar isso como um data warehouse ou para análise de dados? (Caso de uso do usuário final.)
Dica JOBU: Sempre tente resolver um problema ou algo que você acredita que irá ajudar alguém.
Data warehousing é tudo sobre armazenamento e recuperação de dados.
A análise de dados é usada para realizar pesquisas sobre os dados que já foram armazenados para obter uma tendência nos dados.
2. Ingestão
Uma vez que estabelecemos por que estamos fazendo este projeto (motivação) e os casos de uso finais para o projeto, vamos coletar os dados. Encontre diferentes fontes de dados, de preferência fontes de dados em diferentes formatos, como api, csv, sas, parquet, etc. Os dados são grandes, mais de cem mil linhas.
Observação: muitas vezes, a pergunta “qual foi o tamanho dos maiores dados que você lidou?” pergunta é feita em entrevistas.
3. Processamento
Esta fase é onde todo o trabalho é feito. Você projeta a tabela conceitual, como suas tabelas serão projetadas. Você vai usar o esquema em estrela ou o esquema em floco de neve? Como você combinará os objetivos (motivação) com a criação da tabela, restrições de integridade (chave primária, chave estrangeira). Você desenha o Diagrama Entidade-Relacionamento (ER).
Esquema em estrela : Um esquema em estrela é uma estrutura organizacional de banco de dados otimizada para uso em um data warehouse ou BI que usa uma única tabela de fatos grande para armazenar dados transacionais ou medidos e uma ou mais tabelas dimensionais menores que armazenam atributos sobre os dados. É chamado de esquema em estrela porque a tabela de fatos fica no centro do diagrama lógico e as pequenas tabelas dimensionais se ramificam para formar os pontos da estrela.

Esquema Bloco de Neve : Uma variante do esquema em estrela. Aqui, as tabelas são ainda mais normalizadas.
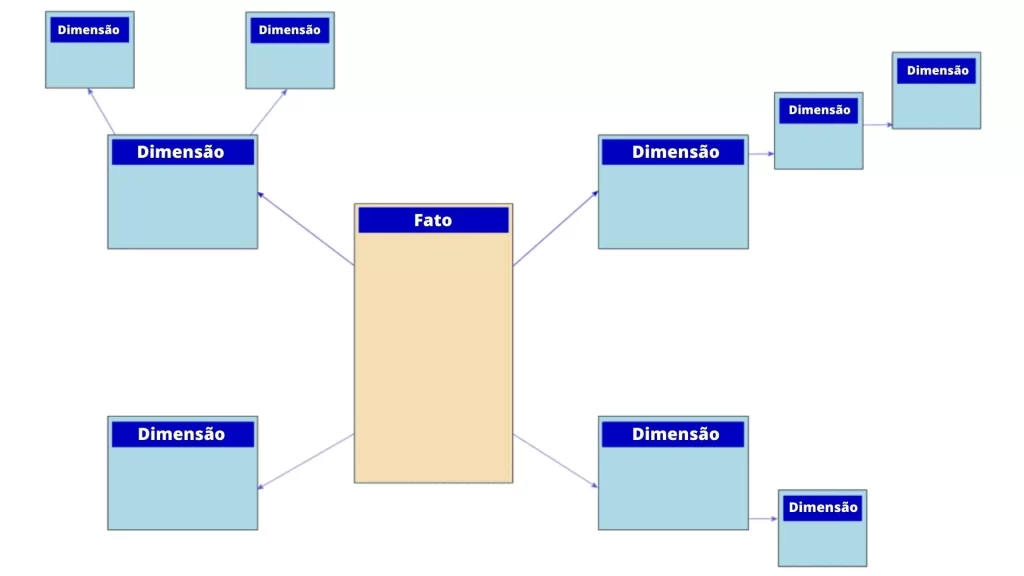
4. Armazenamento
Onde armazenamos os resultados e as tabelas criadas e qual banco de dados usamos? Podemos escolher entre armazenamento colunar ou baseado em linha. Eu gosto de usar o Amazon S3 porque para mim é fácil de usar. Você pode usar Hive ou Microsoft ou GCP.
5. Acesso
Como você exibirá os dados para consumo do usuário final, como um painel do Tableau? ou Grafana?
Habilidades técnicas para arquitetar seu projeto
As diferentes habilidades técnicas que você pode usar.
Linguagens de programação : Python, SQL, NoSQL, Apache Spark, R e Scala. Python e SQL são usados na maioria das vezes.
Habilidades de modelagem de dados : Construa o diagrama ER, conheça os diferentes esquemas – principalmente o esquema floco de neve e estrela, normalização de dados, tabela de fatos e dimensões e armazenamento de dados baseado em linhas e colunas.
Habilidades de Pipeline de Dados (Extrair, Transformar, Carregar) : Criar pipelines de dados (para os quais conhecer Python é importante) e automatizar pipelines de dados como Airflow e Data Swarm.
Plataformas de nuvem : AWS S3, AWS Redshift, GCP e Microsoft Azure.
As plataformas Amazon e Google Cloud são amplamente utilizadas.
Etapas do projeto
Etapa 1: Escopo do projeto e coleta de dados
OBJETIVO: Este projeto visa construir um data warehouse usando o conjunto de dados de imigração dos EUA, enriquecendo os dados com os dados demográficos das cidades dos EUA e os dados de temperatura mundial para análise de dados. Isso é construído para uma tabela de análise de dados.
Para ajudar a responder perguntas como:
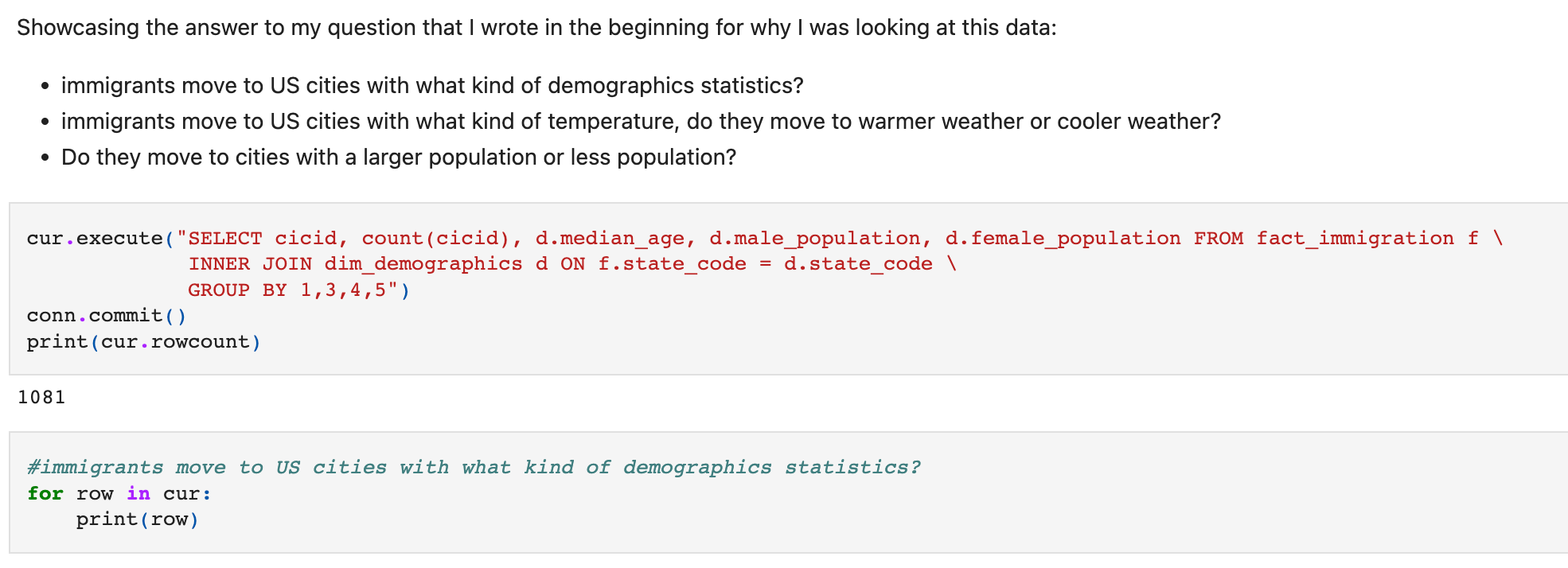
- Imigrantes se mudam para cidades dos EUA com que tipo de demografia/estatística?
- Imigrantes se mudam para cidades dos EUA com que tipo de temperatura? Eles se mudam para um clima mais quente ou um clima mais frio?
- Eles se mudam para cidades com uma população maior ou menor?
Ferramentas que usei para este projeto:
Para este projeto, usei Pandas e NumPy como ferramentas. O Pandas tem ótimas bibliotecas para todas as análises exploratórias de dados que eu queria fazer. Eu usei o NumPy para análise em certas colunas.
Podemos estender ainda mais este projeto com ferramentas como Apache Spark, para análise, pois permite processamento distribuído, e ferramentas em nuvem, como S3 para armazenamento e EMR e Redshift para análise, pois para dados maiores é necessário mais poder de processamento e o uso da CPU .
Usei o notebook Jupyter porque é fácil e intuitivo de usar para análise e criação das tabelas.
Etapa 2. Explorar e acessar os dados
Fontes de dados:
- Dados de I94 de Imigração [Site em inglês]: Esses dados vêm do Escritório Nacional de Turismo e Comércio dos EUA. Um dicionário de dados está incluído na área de trabalho.
- Dados de temperatura mundial [Site em inglês]: Este conjunto de dados veio do Kaggle.
- Dados Demográficos da Cidade dos EUA [Site em inglês]: Esses dados vêm da OpenSoft.
Etapa 3: definir o modelo de dados
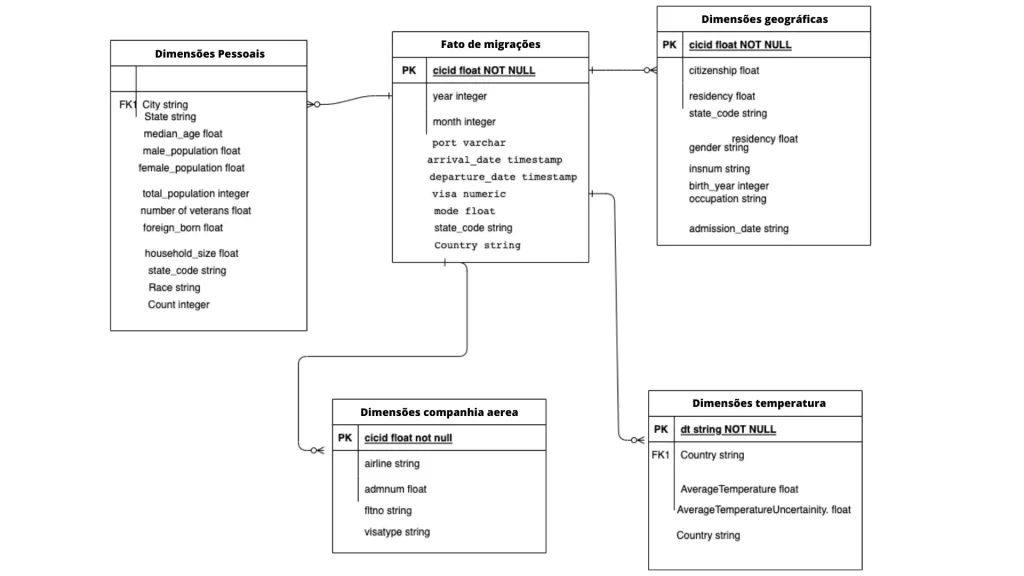
Este exemplo o esquema é em estrela. Uma tabela Fato de imigrações como a Tabela Fato e dimensões companhia aerea, dimensões temperatura, dimensão geográficas e dimensões pessoais como as tabelas dimensionais .
Ao pensar no modelo de dados, estava pensando em criar uma tabela que tenha os fatos sobre os dados de imigração e outra tabela que tenha mais detalhes que possam ajudar a responder minhas perguntas, então a tabela de fatos para os fatos e a tabela de dimensões para os detalhes para a análise.
Por que eu escolhi o esquema em estrela em vez do esquema floco de de neve:
- O esquema em estrela é mais eficiente e uma maneira melhor de organizar os dados.
- O esquema em estrela é super rápido e tem um design simples. Assim, saídas mais rápidas de junções.
Etapa 4: execute o ETL para modelar os dados
Aqui eu modularizei em funções, as etapas de limpeza e criação das tabelas de fatos e dimensões. As verificações de qualidade de dados aconteceram aqui. E também criou o dicionário de dados.
Nota: Dicionários de dados e modularização de pipelines são muito importantes e úteis para a portabilidade do código.
Etapa 5: Completar a redação do projeto
Nesta etapa, concluí executando algumas consultas nas tabelas criadas para mostrar que minhas perguntas podem ser respondidas.
Lembre-se de hospedar seu projeto com um README.md no GitHub.

5 ideias de projetos de engenharia de dados
Sempre que possível faça o seu projeto em inglês isso na divulgação.
Estou apresentando essas ideias de projetos como exemplos de projetos de engenharia de dados de amostra. Você pode criar outra coisa com base nessas ideias.
1. Casos Diários do Covid e Economia Comercial
A pandemia foi e tem sido difícil para todos, mas em relação aos dados, tem sido uma mina de ouro.
Motivação :
- Análise de dados da perda salarial e desemprego devido a casos Covid
- Inflação como resultado da pandemia
Comparando-o com o resto do mundo com o conjunto de dados mundial [Site em inglês]
2. Usando taxa de criminalidade , dados do censo e dados de propriedade
Motivação:
- Como o imposto predial é afetado pela taxa de criminalidade e pelos dados do censo?
- Se a taxa de criminalidade é baixa e a renda média por família é relativamente baixa, como fica o imposto predial?
3. Segurança aérea e dados meteorológicos
Motivação :
- Quantos acidentes ocorreram quando o tempo estava ruim?
- Devemos temer viajar em voos com mau tempo?
Nota lateral: sempre me preocupo em viajar durante o mau tempo, mas os dados mostram o contrário. 🙂
4. API do Twitter e dados de estoque
Motivação :
- Análise de sentimento no Twitter e como o estoque flutua?
Observação: os dados de ações são os dados mais usados para projetos de dados, mas é sempre um desafio experimentá-los.
5. Usando Indicadores de Desenvolvimento Mundial , Estatísticas Educacionais e custos de projetos do Banco Mundial
Motivação:
- Como os projetos do Banco Mundial ajudam no desenvolvimento mundial e nas estatísticas da educação?
- Como as estatísticas da educação se comparam com os indicadores de desenvolvimento mundial para regiões ao redor do mundo?
Você pode tentar o conjunto de dados de imigração, mas talvez faça perguntas diferentes das que eu perguntei.
Isenção de responsabilidade: alguns dos conjuntos de dados podem ser cobrados, mas geralmente são gratuitos para desenvolvedores, especialmente APIs. Geralmente, uso conjuntos de dados gratuitos e disponíveis publicamente.
Conclusão
A Engenharia de Dados, é um campo em crescimento, com mega, tera e peta bytes de dados sendo coletados por setores em todo o mundo. Saber como lidar com os dados e responder a perguntas de negócios com relação aos dados são habilidades obrigatórias. Espero que este artigo tenha sido útil para você enquanto trabalha para melhorar suas habilidades de dados.
Se você tiver alguma dúvida, por favor escreva na seção de comentários abaixo, e eu responderei a eles.
“Cada gota de água em um balde conta.”
Links Úteis
- https://www.projectpro.io/article/real-world-data-engineering-projects-/472
- https://www.dataquest.io/blog/free-datasets-for-projects/
- https://archive.ics.uci.edu/ml/datasets.php
Você também pode ler meu artigo anterior:
“ Como virar um Engenheiro de dados ”
Fonte traduzida: Medium [Em Inglês]