
Consultando dados no Data Lake na AWS
Este artigo é o segundo da série de blogs ‘Foca no data lake’, na qual apresentamos diferentes tecnologias para consultar data lakes na AWS , ou seja, no S3 . No primeiro artigo desta série , discutimos como otimizar data lakes usando formatos de arquivo adequados ( Apache Parquet ) e outros mecanismos de otimização (particionamento) e introduzimos o conceito de data lakehouse.
Também apresentamos um exemplo de como converter dados brutos (a maioria dos dados que chegam em data lakes está em um formato bruto, como CSV) em arquivos Parquet particionados com Athena e Glue na AWS. Nesse exemplo, usamos um conjunto de dados do popular benchmark TPC-H ; essencialmente, geramos três versões do conjunto de dados TPC-H:
- Bruto (CSV) : 100 GB; as maiores tabelas são lineitem com 76GB e orders com 16GB, e são divididas em 80 arquivos.
- Parquets sem divisórias : 31,5 GB; as maiores tabelas são lineitem com 21GB e orders com 4,5GB, e também são divididas em 80 arquivos.
- Parquets Particionados : 32,5 GB; as maiores tabelas, que são particionadas, são lineitem com 21,5GB e orders com 5GB, com uma partição por dia; cada partição tem um arquivo e existem cerca de 2.000 partições para cada tabela. O resto das tabelas são deixadas sem partições.
Nesta postagem do blog e nas próximas, apresentaremos diferentes tecnologias que podem ser usadas para consultar dados em um data lake, para que possamos considerá-las como blocos de construção de um data lakehouse. Usaremos, como um conjunto de dados comum, as três versões que geramos em nosso primeiro blog, conforme visto acima; então certifique-se de ter lido o post do blog antes de prosseguir com este! Cada uma das tecnologias que apresentamos tem seus prós e contras, e escolher qual é a melhor para você depende de muitas variáveis e exige uma análise minuciosa. Ficaremos felizes em ajudá-lo com essa análise, então não hesite em nos contatar .
As consultas que usaremos são aquelas oferecidas no documento de especificação TPC-H . Especificamente, executaremos as consultas 1, 2, 3, 4, 6, 9, 10, 12, 14 e 15. Algumas das características podem ser observadas na tabela a seguir:
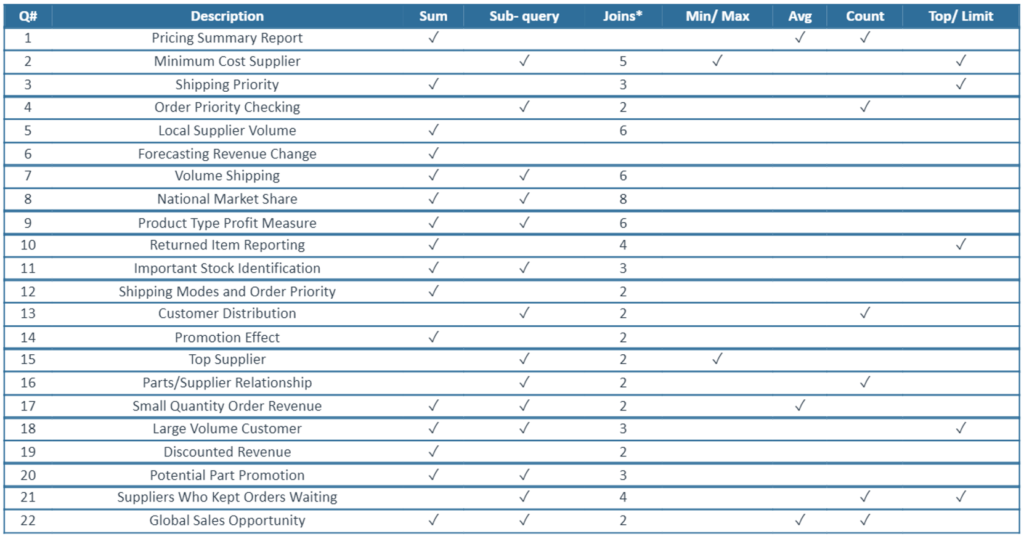
Fonte: Actian
A maioria dessas consultas faz uso de filtros por data, geralmente a coluna l_shipdate da tabela de itens de linha e a coluna o_orderadate da tabela de orders. Esses campos são aqueles pelos quais particionamos as duas tabelas na versão do conjunto de dados em que particionamos as duas maiores tabelas.
Além disso, também discutiremos como as várias tecnologias podem se conectar a ferramentas de relatórios como o Tableau .
Portanto, agora vamos nos concentrar em nossa primeira opção – nesta postagem do blog, explicaremos como usar o Athena para consultar as três versões diferentes do conjunto de dados TPC-H, bem como conectar o Tableau ao Athena.
Apresentando Athena
O Athena é um importante serviço sem servidor da AWS – fundamental para os analistas de dados, engenheiros e cientistas que usam a AWS. É um serviço de consulta intuitivo e fácil de usar, sem necessidade de administração, e você paga apenas pelos dados digitalizados nas consultas que fizer. Aproveitar a compactação de dados ou usar formatos colunares pode reduzir os dados digitalizados e, assim, reduzir os custos.
O Athena é simples de configurar: ele só precisa de um armazenamento de dados como S3 e um Data Catalog em inglês.
Além desses custos, também são faturados os serviços externos utilizados. Como o Athena não tem servidor, ele precisa de serviços extras para conter e estruturar os dados. E lembre-se de que as operações DDL (como CREATE, ALTER e DROP), administração de partições e consultas com falha são gratuitas.
O Athena tem várias limitações que valem a pena observar: há tempos limite de 600 minutos em operações DDL e tempos limite de 30 minutos em DML; também há limitações nas estruturas de dados, com limite de 100 bancos de dados, 100 tabelas por banco de dados e 20.000 partições por tabela. A escalabilidade pode ser um problema para grandes projetos, pois você precisa entrar em contato com a AWS para aumentar os recursos.
Agora que as apresentações terminaram, vamos ao que interessa!
Athena na prática
Uma das características do Athena é a interface fácil de usar: as consultas podem ser executadas em seu próprio editor de consultas, mas há uma limitação de 10 abas abertas simultaneamente.
Criando as definições de esquema
Antes de iniciar a consulta, os dados devem ser preparados.
Observe que o Athena é apenas um mecanismo de consulta sobre o S3, não um armazenamento de dados, e aproveita o Glue Data Catalog para armazenar a definição de bancos de dados e tabelas. Precisaremos criar um banco de dados e definições de esquema de tabela que serão armazenadas no catálogo. Essas definições de esquema podem ser verificadas usando o AWS Glue. Observe também que o Athena armazena metadados e resultados relacionados no S3 em inglês .
Vamos começar com a primeira versão do conjunto de dados, o raw (CSV). A primeira coisa a criar é um banco de dados:
CREATE database IF NOT EXISTS tpc_db;Em seguida, as tabelas podem ser criadas com o seguinte código (exemplo para as orders de tabela ):
CREATE external TABLE tpc_db.orders(
o_orderkey BIGINT,
o_custkey BIGINT,
o_orderstatus varchar(1),
o_totalprice float,
o_orderdate date,
o_orderpriority varchar(15),
o_clerk varchar(15),
o_shippriority int,
o_comment varchar(79)
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS textfile
LOCATION 's3://athena-evaluation/tpc-h-100gb/orders/'; Observe que a palavra-chave ‘external’ é usada para especificar que esta tabela não é armazenada internamente. Isso ocorre porque o Athena não gerencia os dados ou seus metadados; tudo é tratado pelo AWS Glue.
Passando para nossa próxima versão do dataset, os Parquets não particionados, a sintaxe para criar o banco de dados e uma das tabelas externas ( orders ) seriam:
CREATE database IF NOT EXISTS tpc_db_par;
CREATE external TABLE tpc_db_par.orders(
o_orderkey BIGINT,
o_custkey BIGINT,
o_orderstatus varchar(1),
o_totalprice float,
o_orderdate date,
o_orderpriority varchar(15),
o_clerk varchar(15),
o_shippriority int,
o_comment varchar(79)
)
STORED AS Parquet
LOCATION 's3://athena-evaluation/tpc-h-100gb-par/orders/'; Por fim, para a última versão do dataset, os Parquets particionados (somente as maiores tabelas são particionadas), a sintaxe para criar o banco de dados e uma das tabelas externas ( orders ) seriam:
CREATE database IF NOT EXISTS tpc_db_opt;
CREATE external TABLE tpc_db_opt.orders(
o_orderkey BIGINT,
o_custkey BIGINT,
o_orderstatus varchar(1),
o_totalprice float,
o_orderdate date,
o_orderpriority varchar(15),
o_clerk varchar(15),
o_shippriority int,
o_comment varchar(79)
)
PARTITIONED BY (o_orderdate date)
STORED AS Parquet
LOCATION 's3://athena-evaluation/tpc-h-100gb-opt/orders-part/'; Se houver uma partição nos dados, o comando MSCK REPAIR table_name deve ser executado para carregar os metadados necessários e permitir o uso correto da tabela que contém os dados particionados.
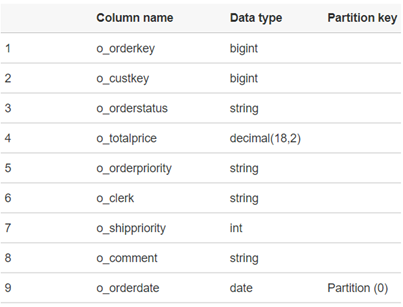
Como mencionado acima, para verificar se tudo correu bem, você pode acessar o AWS Glue e verificar se o banco de dados que foi criado:
Executando as consultas
Depois que tudo estiver configurado, as consultas podem ser executadas. Conforme mencionado acima, executamos 10 consultas da especificação TPC-H para cada versão do conjunto de dados. Observe que ao executar uma consulta, o tempo de execução da consulta, bem como os dados verificados, são mostrados abaixo da caixa de escrita:
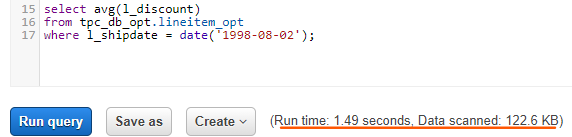
Há também uma guia de histórico na parte superior da janela, onde as execuções anteriores podem ser vistas. Se você clicar em uma das consultas, ela é mostrada no editor de consultas para que o código original seja recuperado.
Ao comparar os resultados da execução das consultas nas três diferentes versões do conjunto de dados, observamos que o uso do Parquet é altamente benéfico, não apenas por reduzir o custo, mas também por ser mais rápido de ler. Em média, observamos um fator de melhoria de 2-3x ao usar o Parquet em comparação com o CSV. Faz sentido, já que o formato Parquet é colunar, o que melhora o desempenho em consultas de análise como as que a equipe de BI faria, e também é menor por ser binário e compactado.
Em relação ao particionamento, embora os tempos de consulta diminuam em geral, não há muita diferença no tempo de execução em comparação com o Parquet não particionado, pois o conjunto de dados que usamos não era grande o suficiente. Com um conjunto de dados maior, uma melhoria no tempo seria perceptível. Embora não seja tão diferente, a quantidade de dados verificados é um pouco menor com o particionamento, o que significa menos custo.
Observe que cada consulta usa recursos de computação independentes, portanto, com alta simultaneidade de usuários, não há mecanismos para otimizar os recursos de computação e os custos podem aumentar muito rapidamente.
Conexão do Tableau
A conexão entre o Athena e o Tableau é simples de fazer: existe a opção de usar o Athena como fonte de dados, embora seja necessário instalar um driver para se conectar ao Athena primeiro.

A configuração da conexão requer o endpoint do servidor ao qual você está se conectando, dependendo da região. O nome do servidor por região pode ser encontrado no guia de referência de cotas e endpoints do Amazon Athena na documentação da AWS.
Também requer um diretório S3 que será usado como diretório de teste para salvar dados e metadados relacionados às consultas executadas no Athena. Como credenciais de identificação, são usadas chaves de acesso. Para saber mais sobre chaves de acesso, leia o guia do usuário Gerenciando chaves de acesso para usuários do IAM na documentação da AWS. Depois de entrar, use o Tableau normalmente:
Observe que o Tableau não funciona bem com JOINs quando grandes tabelas estão envolvidas, portanto, em alguns casos, é aconselhável ter esses JOINs pré-calculados no nível do banco de dados/data lake antes de usar o conjunto de dados para fins de relatório para evitar consultas demoradas.
Além disso, pode ajudar a criar tabelas agregadas dependendo do caso de uso. Além disso, o Tableau tem seu próprio planejamento de consulta, e isso pode representar um certo risco com o Athena, pois o usuário pode não controlar a quantidade de dados verificados e isso pode levar a um custo inesperadamente alto. Portanto, ao usar o Athena com o Tableau, você realmente deve saber o que está fazendo e deve ter estruturado muito bem os dados subjacentes.
Athena – Prós e Contras
Neste artigo apresentamos o Athena, e as vantagens que gostaríamos de destacar são:
- É um serviço de consulta sem servidor que é muito fácil de começar e não exige que você configure nada.
- Permite consultar diretamente ao S3 sem infraestrutura.
- Preparar o Athena para consultar dados no S3 é tão fácil quanto executar algumas instruções DDL para definir esquemas em um catálogo.
- Seu preço é pay-per-query e é muito simples monitorar os custos.
- É uma excelente opção para consultas ad hoc no lago (S3) relativamente simples e, se o data lake do S3 estiver organizado adequadamente, obteremos um desempenho muito bom. Testamos a execução das mesmas consultas com as três versões diferentes do mesmo conjunto de dados e vimos o impacto (melhoria do fator 2-3) de usar um formato de arquivo otimizado, como o Parquet. Também vimos um pequeno ganho ao usar o particionamento (nosso conjunto de dados era muito pequeno para ver um ganho significativo).
- É totalmente compatível com o AWS Glue.
No entanto, embora acreditemos que Athena é ótima, há algumas coisas a serem consideradas:
- A desvantagem de ser sem servidor e totalmente gerenciado é que há muito poucas opções na administração e ajuste do próprio mecanismo. O ajuste do Athena não é imediato, você precisa entrar em contato com a AWS para aumentar seus recursos.
- O Athena foi projetado para executar consultas relativamente simples, e os usuários devem saber o que estão fazendo, especialmente ao lidar com ferramentas de relatórios, ou podem ocorrer custos inesperados.
- Como cada consulta é independente, ao lidar com muitos usuários ou cenários altamente simultâneos, o próprio mecanismo e, mais importante, seu custo, não pode realmente aproveitar a simultaneidade para otimizar a si mesmo.
Conclusão
O Athena é uma boa opção para consultar dados em lagos da AWS, mas em alguns casos pode não ser a melhor. Em algumas situações, como quando estão envolvidas consultas complexas, ou há um uso extensivo de ferramentas de BI, ou alta simultaneidade, é preciso pensar com muito cuidado sobre como selecionar a melhor abordagem.
Uma abordagem é otimizar ainda mais as tabelas do data lake criando tabelas unidas ou agregadas; outra abordagem é usar uma tecnologia de armazenamento de dados como o Redshift , que é exatamente o que abordaremos em nossa próxima postagem no blog. O Redshift também permite consultar diretamente no S3 com Spectrum, bem como carregar dados para o warehouse – aumentando assim o desempenho em consultas complexas e evitando a cobrança por dados adicionais.
Se você tem interesse em usar o Athena ou qualquer outro serviço da AWS, ou está em dúvida sobre qual é a arquitetura mais adequada para sua plataforma de dados, basta entrar em contato conosco . Aqui na ClearPeaks temos uma ampla experiência com tecnologias em nuvem , e podemos ajudá-lo a decidir a melhor opção para seus projetos.
Fonte: Clearpeaks