
Tutorial do TensorFlow 2: A modelagem preditiva com aprendizado profundo é uma habilidade que os desenvolvedores modernos precisam conhecer.
TensorFlow é a principal estrutura de aprendizado profundo de código aberto desenvolvida e mantida pelo Google. Embora usar o TensorFlow diretamente possa ser desafiador, a API tf.keras moderna traz a simplicidade e a facilidade de uso do Keras para o projeto do TensorFlow.
Usar tf.keras permite projetar, ajustar, avaliar e usar modelos de aprendizado profundo para fazer previsões em apenas algumas linhas de código. Ele torna as tarefas comuns de aprendizado profundo, como modelagem preditiva de classificação e regressão, acessíveis para desenvolvedores médios que procuram fazer as coisas.
Neste tutorial, você descobrirá um guia passo a passo para desenvolver modelos de aprendizado profundo no TensorFlow usando a API tf.keras.
Depois de concluir este tutorial, você saberá:
- A diferença entre Keras e tf.keras e como instalar e confirmar se o TensorFlow está funcionando.
- O ciclo de vida de 5 etapas dos modelos tf.keras e como usar as APIs sequenciais e funcionais.
- Como desenvolver modelos MLP, CNN e RNN com tf.keras para regressão, classificação e previsão de séries temporais.
- Como usar os recursos avançados da API tf.keras para inspecionar e diagnosticar seu modelo.
- Como melhorar o desempenho do seu modelo tf.keras reduzindo o overfitting e acelerando o treinamento.
Este é um tutorial amplo e muito divertido. Você pode querer marcá-lo.
Os exemplos são pequenos e focados; você pode terminar este tutorial em cerca de 60 minutos.
Vamos começar:

Como desenvolver modelos de aprendizado profundo com tf.keras
Visão geral do tutorial do TensorFlow
Este tutorial foi desenvolvido para ser sua introdução completa ao tf.keras para seu projeto de aprendizado profundo.
O foco está no uso da API para tarefas comuns de desenvolvimento de modelo de aprendizado profundo; não vamos mergulhar na matemática e na teoria do aprendizado profundo. Para isso, recomendo começar por este excelente livro .
A melhor maneira de aprender aprendizado profundo em python é fazendo. Mergulhe. Você pode voltar para mais teoria mais tarde.
Eu projetei cada exemplo de código para usar as melhores práticas e ser autônomo para que você possa copiar e colar diretamente em seu projeto e adaptá-lo às suas necessidades específicas. Isso lhe dará uma grande vantagem para tentar descobrir a API apenas a partir da documentação oficial.
Você pode fazer um aprendizado profundo em Python!
Trabalhe no tutorial em seu próprio ritmo.
Você não precisa entender tudo (pelo menos não agora) . Seu objetivo é executar o tutorial de ponta a ponta e obter resultados. Você não precisa entender tudo na primeira passagem. Liste suas perguntas conforme você avança. Faça uso intensivo da documentação da API para aprender sobre todas as funções que você está usando.
Você não precisa saber matemática primeiro . Matemática é uma forma compacta de descrever como funcionam os algoritmos, especificamente ferramentas de álgebra linear , probabilidade e estatística . Essas não são as únicas ferramentas que você pode usar para aprender como funcionam os algoritmos. Você também pode usar código e explorar o comportamento do algoritmo com diferentes entradas e saídas. Saber a matemática não dirá qual algoritmo escolher ou como melhor configurá-lo. Você só pode descobrir isso por meio de experimentos cuidadosos e controlados.
Você não precisa saber como funcionam os algoritmos . É importante saber sobre as limitações e como configurar algoritmos de aprendizado profundo. Mas aprender sobre algoritmos pode vir mais tarde. Você precisa desenvolver esse conhecimento de algoritmo lentamente, por um longo período de tempo. Hoje, comece ficando confortável com a plataforma.
Você não precisa ser um programador Python . A sintaxe da linguagem Python pode ser intuitiva se você for novo nela. Assim como em outras linguagens, concentre-se em chamadas de função (por exemplo, function ()) e atribuições (por exemplo, a = “b”). Isso o levará a maior parte do caminho. Você é um desenvolvedor, então você sabe aprender o básico de uma linguagem muito rápido. Basta começar e mergulhar nos detalhes mais tarde.
Você não precisa ser um especialista em aprendizado profundo . Você pode aprender sobre os benefícios e limitações de vários algoritmos posteriormente, e há muitos posts que você pode ler mais tarde para retocar nas etapas de um projeto de aprendizado profundo e a importância de avaliar a habilidade do modelo usando validação cruzada.
1. Instale TensorFlow e tf.keras
Nesta seção, você descobrirá o que é tf.keras, como instalá-lo e como confirmar se ele está instalado corretamente.
1.1 O que são Keras e tf.keras?
Keras é uma biblioteca de aprendizado profundo de código aberto escrita em Python.
O projeto foi iniciado em 2015 por François Chollet . Ele rapidamente se tornou uma estrutura popular para desenvolvedores, tornando-se uma das, se não a mais popular, bibliotecas de aprendizado profundo.
Durante o período de 2015-2019, o desenvolvimento de modelos de aprendizado profundo usando bibliotecas matemáticas como TensorFlow, Theano e PyTorch foi complicado, exigindo dezenas ou até centenas de linhas de código para realizar as tarefas mais simples. O foco dessas bibliotecas era pesquisa, flexibilidade e velocidade, não facilidade de uso.
Keras era popular porque a API era limpa e simples, permitindo que modelos de aprendizado profundo padrão fossem definidos, ajustados e avaliados em apenas algumas linhas de código.
A razão secundária Keras levou-off foi porque permitiu que você use qualquer um entre a gama de aprendizagem profunda bibliotecas matemáticas populares como o back-end (por exemplo, usado para executar o cálculo), como TensorFlow , Theano , e mais tarde, CNTK . Isso permitiu que o poder dessas bibliotecas fosse aproveitado (por exemplo, GPUs) com uma interface muito limpa e simples.
Em 2019, o Google lançou uma nova versão de sua biblioteca de aprendizado profundo TensorFlow (TensorFlow 2) que integrou a API Keras diretamente e promoveu essa interface como a interface padrão ou padrão para desenvolvimento de aprendizado profundo na plataforma.
Essa integração é comumente conhecida como interface tf.keras ou API (” tf ” é a abreviação de ” TensorFlow “). Isso é para distingui-lo do chamado projeto autônomo de código aberto Keras.
- Keras autônomo . O projeto autônomo de código aberto compatível com os back-ends TensorFlow, Theano e CNTK.
- tf.keras . A API Keras integrada ao TensorFlow 2.
A implementação da API Keras em Keras é conhecida como “ tf.keras ” porque este é o idioma Python usado ao fazer referência à API. Primeiro, o módulo TensorFlow é importado e denominado “ tf “; em seguida, os elementos da API Keras são acessados por meio de chamadas para tf.keras ; por exemplo:
# example of tf.keras python idiom
import tensorflow as tf
# use keras API
model = tf.keras.Sequential()
...Eu geralmente não uso esse idioma; Não acho que seja uma leitura limpa.
Considerando que o TensorFlow era o back-end padrão de fato para o projeto de código aberto Keras, a integração significa que uma única biblioteca agora pode ser usada em vez de duas bibliotecas separadas. Além disso, o projeto Keras autônomo agora recomenda que todos os desenvolvimentos Keras futuros usem a API tf.keras .
No momento, recomendamos que os usuários do Keras que usam o Keras de vários back-ends com o back-end do TensorFlow alternem para tf.keras no TensorFlow 2.0. O tf.keras tem uma manutenção melhor e uma integração melhor com os recursos do TensorFlow (execução rápida, suporte de distribuição e outros).
– Página inicial do projeto Keras , acessado em dezembro de 2019.
1.2 Como instalar o TensorFlow
Antes de instalar o TensorFlow, certifique-se de ter o Python instalado, como o Python 3.6 ou superior.
Se você não tem o Python instalado, você pode instalá-lo usando o Anaconda.
Há muitas maneiras de instalar a biblioteca de aprendizado profundo de código aberto TensorFlow.
A maneira mais comum, e talvez a mais simples, de instalar o TensorFlow em sua estação de trabalho é usando pip .
Por exemplo, na linha de comando, você pode digitar:
| sudo pip install tensorflow |
Se preferir usar um método de instalação mais específico para sua plataforma ou gerenciador de pacotes, você pode ver uma lista completa de instruções de instalação aqui:
Não há necessidade de configurar a GPU agora.
Todos os exemplos neste tutorial funcionarão bem em uma CPU moderna. Se você deseja configurar o TensorFlow para sua GPU, pode fazer isso depois de concluir este tutorial. Não se distraia!
1.3 Como confirmar se o TensorFlow está instalado
Depois que o TensorFlow estiver instalado, é importante confirmar se a biblioteca foi instalada com sucesso e se você pode começar a usá-la.
Não pule esta etapa .
Se o TensorFlow não estiver instalado corretamente ou gerar um erro nesta etapa, você não conseguirá executar os exemplos mais tarde.
Crie um novo arquivo chamado versions.py e copie e cole o código a seguir no arquivo.
| #check version import tensorflow print(tensorflow.__version__) |
Salve o arquivo, abra a linha de comando e mude o diretório para onde salvou o arquivo.
Em seguida, digite:
| python versions.py |
Você deve ver uma saída como a seguinte:
| 2.2.0 |
Isso confirma se o TensorFlow está instalado corretamente e se todos estamos usando a mesma versão.
Qual versão você conseguiu?
Poste sua saída nos comentários abaixo.
Isso também mostra como executar um script Python a partir da linha de comando. Eu recomendo executar todo o código da linha de comando dessa maneira, e não de um notebook ou IDE .
Se você receber mensagens de aviso
Às vezes, ao usar a API tf.keras , você pode ver avisos impressos.
Isso pode incluir mensagens de que seu hardware oferece suporte a recursos que sua instalação do TensorFlow não foi configurada para usar.
Alguns exemplos em minha estação de trabalho incluem:
Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
XLA service 0x7fde3f2e6180 executing computations on platform Host. Devices:
StreamExecutor device (0): Host, Default VersionEles não são sua culpa. Você não fez nada de errado .
Estas são mensagens informativas e não impedirão a execução do seu código. Você pode ignorar com segurança mensagens desse tipo por enquanto.
É uma decisão de design intencional feita pela equipe do TensorFlow para mostrar essas mensagens de aviso. Uma desvantagem dessa decisão é que ela confunde os iniciantes e treina os desenvolvedores a ignorar todas as mensagens, incluindo aquelas que potencialmente podem impactar a execução.
Agora que você sabe o que é tf.keras, como instalar o TensorFlow e como confirmar se seu ambiente de desenvolvimento está funcionando, vamos dar uma olhada no ciclo de vida dos modelos de aprendizado profundo no TensorFlow.
2. Ciclo de vida do modelo de aprendizado profundo
Nesta seção, você descobrirá o ciclo de vida de um modelo de aprendizado profundo e as duas APIs tf.keras que você pode usar para definir modelos.
2.1 O ciclo de vida do modelo de 5 etapas
Um modelo tem um ciclo de vida e esse conhecimento muito simples fornece a base para a modelagem de um conjunto de dados e a compreensão da API tf.keras.
As cinco etapas do ciclo de vida são as seguintes:
- Defina o modelo.
- Compile o modelo.
- Ajuste o modelo.
- Avalie o modelo.
- Fazer previsões.
Vamos dar uma olhada mais de perto em cada etapa.
Defina o modelo
Definir o modelo requer que você primeiro selecione o tipo de modelo de que precisa e, em seguida, escolha a arquitetura ou topologia de rede.
Do ponto de vista da API, isso envolve definir as camadas do modelo, configurar cada camada com um número de nós e função de ativação e conectar as camadas em um modelo coeso.
Os modelos podem ser definidos com a API Sequencial ou com a API Funcional, e veremos isso na próxima seção.
...
# define the model
model = ...Compile o modelo
Compilar o modelo requer que você primeiro selecione uma função de perda que deseja otimizar, como erro quadrático médio ou entropia cruzada.
Também requer que você selecione um algoritmo para realizar o procedimento de otimização, geralmente descida gradiente estocástica ou uma variação moderna, como Adam. Também pode exigir que você selecione quaisquer métricas de desempenho para controlar durante o processo de treinamento do modelo.
Do ponto de vista da API, isso envolve chamar uma função para compilar o modelo com a configuração escolhida, que irá preparar as estruturas de dados apropriadas necessárias para o uso eficiente do modelo que você definiu.
O otimizador pode ser especificado como uma string para uma classe de otimizador conhecida, por exemplo, ‘ sgd ‘ para descida gradiente estocástica, ou você pode configurar uma instância de uma classe de otimizador e usá-la.
Para obter uma lista de otimizadores compatíveis, consulte:
...
# compile the model
opt = SGD(learning_rate=0.01, momentum=0.9)
model.compile(optimizer=opt, loss='binary_crossentropy')As três funções de perda mais comuns são:
- ‘ binary_crossentropy ‘ para classificação binária.
- ‘ sparse_categorical_crossentropy ‘ para classificação multiclasse .
- ‘ mse ‘ (erro quadrático médio) para regressão.
...
# compile the model
model.compile(optimizer='sgd', loss='mse')Para obter uma lista das funções de perda suportadas, consulte:
As métricas são definidas como uma lista de strings para funções de métricas conhecidas ou uma lista de funções a serem chamadas para avaliar as previsões.
Para obter uma lista de métricas compatíveis, consulte:
...
# compile the model
model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy'])Ajustar o modelo
Ajustar o modelo requer que você primeiro selecione a configuração de treinamento, como o número de épocas (loops no conjunto de dados de treinamento) e o tamanho do lote (número de amostras em uma época usadas para estimar o erro do modelo).
O treinamento aplica o algoritmo de otimização escolhido para minimizar a função de perda escolhida e atualiza o modelo usando a retropropagação do algoritmo de erro.
Ajustar o modelo é a parte lenta de todo o processo e pode levar de segundos a horas ou dias, dependendo da complexidade do modelo, do hardware que você está usando e do tamanho do conjunto de dados de treinamento.
Da perspectiva da API, isso envolve chamar uma função para realizar o processo de treinamento. Esta função irá bloquear (não retornar) até que o processo de treinamento termine.
...
# fit the model
model.fit(X, y, epochs=100, batch_size=32)Ao ajustar o modelo, uma barra de progresso resumirá o status de cada época e o processo geral de treinamento. Isso pode ser simplificado para um relatório simples de desempenho do modelo a cada época, definindo o argumento “ verboso ” para 2. Todas as saídas podem ser desligadas durante o treinamento definindo “ verboso ” para 0.
...
# fit the model
model.fit(X, y, epochs=100, batch_size=32, verbose=0)Avalie o modelo
Avaliar o modelo requer que você primeiro escolha um conjunto de dados de validação usado para avaliar o modelo. Devem ser dados não usados no processo de treinamento para que possamos obter uma estimativa imparcial do desempenho do modelo ao fazer previsões sobre novos dados.
A velocidade da avaliação do modelo é proporcional à quantidade de dados que você deseja usar para a avaliação, embora seja muito mais rápida do que o treinamento, pois o modelo não é alterado.
Do ponto de vista da API, isso envolve chamar uma função com o conjunto de dados de validação e obter uma perda e talvez outras métricas que podem ser relatadas.
...
# evaluate the model
loss = model.evaluate(X, y, verbose=0)Fazer uma previsão
Fazer uma previsão é a etapa final do ciclo de vida. É por isso que queríamos o modelo em primeiro lugar.
Exige que você tenha novos dados para os quais é necessária uma previsão, por exemplo, onde você não tem os valores alvo.
De uma perspectiva de API, você simplesmente chama uma função para fazer uma previsão de um rótulo de classe, probabilidade ou valor numérico: tudo o que você projetou para prever em seu modelo.
Você pode querer salvar o modelo e depois carregá-lo para fazer previsões. Você também pode escolher ajustar um modelo em todos os dados disponíveis antes de começar a usá-lo.
Agora que estamos familiarizados com o ciclo de vida do modelo, vamos dar uma olhada nas duas maneiras principais de usar a API tf.keras para construir modelos: sequencial e funcional.
...
# make a prediction
yhat = model.predict(X)
2.2 API de modelo sequencial (simples)
A API do modelo sequencial é a mais simples e é a API que eu recomendo, especialmente ao começar.
É referido como “ sequencial ” porque envolve a definição de uma classe Sequencial e a adição de camadas ao modelo, uma a uma, de maneira linear, da entrada à saída.
O exemplo abaixo define um modelo Sequential MLP que aceita oito entradas, tem uma camada oculta com 10 nós e, em seguida, uma camada de saída com um nó para prever um valor numérico.
# example of a model defined with the sequential api
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
# define the model
model = Sequential()
model.add(Dense(10, input_shape=(8,)))
model.add(Dense(1))Observe que a camada visível da rede é definida pelo argumento “ input_shape ” na primeira camada oculta. Isso significa que no exemplo acima, o modelo espera que a entrada para uma amostra seja um vetor de oito números.
A API sequencial é fácil de usar porque você continua chamando model.add () até adicionar todas as suas camadas.
Por exemplo, aqui está um MLP profundo com cinco camadas ocultas.
# example of a model defined with the sequential api
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
# define the model
model = Sequential()
model.add(Dense(100, input_shape=(8,)))
model.add(Dense(80))
model.add(Dense(30))
model.add(Dense(10))
model.add(Dense(5))
model.add(Dense(1))2.3 API de modelo funcional (avançado)
A API funcional é mais complexa, mas também mais flexível.
Envolve conectar explicitamente a saída de uma camada à entrada de outra camada. Cada conexão é especificada.
Primeiro, uma camada de entrada deve ser definida por meio da classe Input e a forma de uma amostra de entrada é especificada. Devemos manter uma referência à camada de entrada ao definir o modelo.
...
# define the layers
x_in = Input(shape=(8,))Em seguida, uma camada totalmente conectada pode ser conectada à entrada chamando a camada e passando a camada de entrada. Isso retornará uma referência à conexão de saída nesta nova camada.
...
x = Dense(10)(x_in)Podemos então conectar isso a uma camada de saída da mesma maneira.
...
x_out = Dense(1)(x)Uma vez conectado, definimos um objeto Model e especificamos as camadas de entrada e saída. O exemplo completo está listado abaixo.
#example of a model defined with the functional api
from tensorflow.keras import Model
from tensorflow.keras import Input
from tensorflow.keras.layers import Dense
# define the layers
x_in = Input(shape=(8,))
x = Dense(10)(x_in)
x_out = Dense(1)(x)
# define the model
model = Model(inputs=x_in, outputs=x_out)Como tal, permite designs de modelo mais complicados, como modelos que podem ter vários caminhos de entrada (vetores separados) e modelos que têm vários caminhos de saída (por exemplo, uma palavra e um número).
A API funcional pode ser muito divertida quando você se acostuma.
Agora que estamos familiarizados com o ciclo de vida do modelo e as duas APIs que podem ser usadas para definir modelos, vamos examinar o desenvolvimento de alguns modelos padrão.
3. Como desenvolver modelos de aprendizado profundo
Nesta seção, você descobrirá como desenvolver, avaliar e fazer previsões com modelos de aprendizado profundo padrão, incluindo Perceptrons Multicamadas (MLP), Redes Neurais Convolucionais (CNNs) e Redes Neurais Recorrentes (RNNs).
3.1 Desenvolver Modelos Perceptron Multicamadas
Um modelo Multilayer Perceptron, ou MLP para breve, é um modelo de rede neural totalmente conectada padrão.
É composto de camadas de nós onde cada nó é conectado a todas as saídas da camada anterior e a saída de cada nó é conectada a todas as entradas para os nós da próxima camada.
Um MLP é criado com uma ou mais camadas densas . Este modelo é apropriado para dados tabulares, ou seja, dados como aparecem em uma tabela ou planilha com uma coluna para cada variável e uma linha para cada variável. Existem três problemas de modelagem preditiva que você pode querer explorar com um MLP; eles são classificação binária, classificação multiclasse e regressão.
Vamos ajustar um modelo em um conjunto de dados real para cada um desses casos.
Observe que os modelos nesta seção são eficazes, mas não otimizados. Veja se você consegue melhorar o desempenho deles. Publique suas descobertas nos comentários abaixo.
MLP para classificação binária
Usaremos o conjunto de dados de classificação binária (duas classes) da Ionosphere para demonstrar um MLP para classificação binária.
Este conjunto de dados envolve prever se uma estrutura está na atmosfera ou não com retornos de radar.
O conjunto de dados será baixado automaticamente usando o Pandas , mas você pode aprender mais sobre isso aqui.
Usaremos um LabelEncoder para codificar os rótulos de string para valores inteiros 0 e 1. O modelo será ajustado em 67 por cento dos dados e os 33 por cento restantes serão usados para avaliação, divididos usando a função train_test_split () .
O modelo prevê a probabilidade da classe 1 e usa a função de ativação sigmóide.
O exemplo completo está listado abaixo.
# mlp for binary classification
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
# load the dataset
path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/ionosphere.csv'
df = read_csv(path, header=None)
# split into input and output columns
X, y = df.values[:, :-1], df.values[:, -1]
# ensure all data are floating point values
X = X.astype('float32')
# encode strings to integer
y = LabelEncoder().fit_transform(y)
# split into train and test datasets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# determine the number of input features
n_features = X_train.shape[1]
# define model
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(8, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# fit the model
model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=0)
# evaluate the model
loss, acc = model.evaluate(X_test, y_test, verbose=0)
print('Test Accuracy: %.3f' % acc)
# make a prediction
row = [1,0,0.99539,-0.05889,0.85243,0.02306,0.83398,-0.37708,1,0.03760,0.85243,-0.17755,0.59755,-0.44945,0.60536,-0.38223,0.84356,-0.38542,0.58212,-0.32192,0.56971,-0.29674,0.36946,-0.47357,0.56811,-0.51171,0.41078,-0.46168,0.21266,-0.34090,0.42267,-0.54487,0.18641,-0.45300]
yhat = model.predict([row])
print('Predicted: %.3f' % yhat)Executar o exemplo primeiro relata a forma do conjunto de dados, depois ajusta o modelo e o avalia no conjunto de dados de teste. Finalmente, uma previsão é feita para uma única linha de dados.
Nota : Seus resultados podem variar devido à natureza estocástica do algoritmo ou procedimento de avaliação, ou diferenças na precisão numérica. Considere executar o exemplo algumas vezes e compare o resultado médio.
Quais resultados você conseguiu? Você pode mudar o modelo para fazer melhor?
Publique suas descobertas nos comentários abaixo.
Nesse caso, podemos ver que o modelo alcançou uma precisão de classificação de cerca de 94 por cento e, em seguida, previu uma probabilidade de 0,9 de que uma linha de dados pertencesse à classe 1.
(235, 34) (116, 34) (235,) (116,)
Test Accuracy: 0.940
Predicted: 0.991MLP para classificação multiclasse
Usaremos o conjunto de dados de classificação multiclasse de flores Iris para demonstrar um MLP para classificação multiclasse.
Este problema envolve prever as espécies de flores de íris dadas as medidas da flor.
O conjunto de dados será baixado automaticamente usando o Pandas, mas você pode aprender mais sobre isso aqui.
Por se tratar de uma classificação multiclasse, o modelo deve possuir um nó para cada classe da camada de saída e utilizar a função de ativação softmax. A função de perda é a ‘ sparse_categorical_crossentropy ‘, que é apropriada para rótulos de classe codificados por inteiro (por exemplo, 0 para uma classe, 1 para a próxima classe, etc.)
O exemplo completo de ajuste e avaliação de um MLP no conjunto de dados de flores da íris está listado abaixo.
# mlp for multiclass classification
from numpy import argmax
from pandas import read_csv
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
# load the dataset
path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv'
df = read_csv(path, header=None)
# split into input and output columns
X, y = df.values[:, :-1], df.values[:, -1]
# ensure all data are floating point values
X = X.astype('float32')
# encode strings to integer
y = LabelEncoder().fit_transform(y)
# split into train and test datasets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# determine the number of input features
n_features = X_train.shape[1]
# define model
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(8, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(3, activation='softmax'))
# compile the model
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# fit the model
model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=0)
# evaluate the model
loss, acc = model.evaluate(X_test, y_test, verbose=0)
print('Test Accuracy: %.3f' % acc)
# make a prediction
row = [5.1,3.5,1.4,0.2]
yhat = model.predict([row])
print('Predicted: %s (class=%d)' % (yhat, argmax(yhat)))Executar o exemplo primeiro relata a forma do conjunto de dados, depois ajusta o modelo e o avalia no conjunto de dados de teste. Finalmente, uma previsão é feita para uma única linha de dados.
Nota : Seus resultados podem variar devido à natureza estocástica do algoritmo ou procedimento de avaliação, ou diferenças na precisão numérica. Considere executar o exemplo algumas vezes e compare o resultado médio.
Quais resultados você conseguiu? Você pode mudar o modelo para fazer melhor?
Publique suas descobertas nos comentários abaixo.
Nesse caso, podemos ver que o modelo alcançou uma precisão de classificação de cerca de 98 por cento e então previu uma probabilidade de uma linha de dados pertencer a cada classe, embora a classe 0 tenha a maior probabilidade.
(100, 4) (50, 4) (100,) (50,)
Test Accuracy: 0.980
Predicted: [[0.8680804 0.12356871 0.00835086]] (class=0)MLP para regressão
Usaremos o conjunto de dados de regressão de habitação de Boston para demonstrar um MLP para modelagem preditiva de regressão.
Esse problema envolve a previsão do valor da casa com base nas propriedades da casa e do bairro.
O conjunto de dados será baixado automaticamente usando o Pandas, mas você pode aprender mais sobre isso aqui.
- Conjunto de dados de habitação de Boston (csv) .
- Descrição do conjunto de dados de habitação de Boston (csv) .
Este é um problema de regressão que envolve a previsão de um único valor numérico. Como tal, a camada de saída tem um único nó e usa a função de ativação padrão ou linear (sem função de ativação). A perda do erro quadrático médio (mse) é minimizada ao ajustar o modelo.
O exemplo completo de adaptação e avaliação de um MLP no conjunto de dados habitacionais de Boston está listado abaixo.
# mlp for regression
from numpy import sqrt
from pandas import read_csv
from sklearn.model_selection import train_test_split
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
# load the dataset
path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/housing.csv'
df = read_csv(path, header=None)
# split into input and output columns
X, y = df.values[:, :-1], df.values[:, -1]
# split into train and test datasets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# determine the number of input features
n_features = X_train.shape[1]
# define model
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(8, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(1))
# compile the model
model.compile(optimizer='adam', loss='mse')
# fit the model
model.fit(X_train, y_train, epochs=150, batch_size=32, verbose=0)
# evaluate the model
error = model.evaluate(X_test, y_test, verbose=0)
print('MSE: %.3f, RMSE: %.3f' % (error, sqrt(error)))
# make a prediction
row = [0.00632,18.00,2.310,0,0.5380,6.5750,65.20,4.0900,1,296.0,15.30,396.90,4.98]
yhat = model.predict([row])
print('Predicted: %.3f' % yhat)Executar o exemplo primeiro relata a forma do conjunto de dados, em seguida, ajusta o modelo e o avalia no conjunto de dados de teste. Finalmente, uma previsão é feita para uma única linha de dados.
Nota : Seus resultados podem variar devido à natureza estocástica do algoritmo ou procedimento de avaliação, ou diferenças na precisão numérica. Considere executar o exemplo algumas vezes e compare o resultado médio.
Quais resultados você conseguiu? Você pode mudar o modelo para fazer melhor?
Publique suas descobertas nos comentários abaixo.
Neste caso, podemos ver que o modelo atingiu um MSE de cerca de 60 que é um RMSE de cerca de 7 (unidades são milhares de dólares). Um valor de cerca de 26 é então previsto para o único exemplo.
(339, 13) (167, 13) (339,) (167,)
MSE: 60.751, RMSE: 7.794
Predicted: 26.983.2 Desenvolver modelos de rede neural convolucional
Redes neurais convolucionais, ou CNNs, são um tipo de rede projetada para a entrada de imagens.
Eles são compostos de modelos com camadas convolucionais que extraem recursos (chamados de mapas de recursos) e camadas de pool que destilam recursos até os elementos mais salientes.
CNNs são mais adequados para tarefas de classificação de imagens, embora possam ser usados em uma ampla gama de tarefas que tomam imagens como entrada.
Uma tarefa popular de classificação de imagens é a classificação de dígitos manuscritos MNIST . Envolve dezenas de milhares de dígitos manuscritos que devem ser classificados como um número entre 0 e 9.
A API tf.keras fornece uma função conveniente para baixar e carregar esse conjunto de dados diretamente.
O exemplo abaixo carrega o conjunto de dados e plota as primeiras imagens.
# example of loading and plotting the mnist dataset
from tensorflow.keras.datasets.mnist import load_data
from matplotlib import pyplot
# load dataset
(trainX, trainy), (testX, testy) = load_data()
# summarize loaded dataset
print('Train: X=%s, y=%s' % (trainX.shape, trainy.shape))
print('Test: X=%s, y=%s' % (testX.shape, testy.shape))
# plot first few images
for i in range(25):
# define subplot
pyplot.subplot(5, 5, i+1)
# plot raw pixel data
pyplot.imshow(trainX[i], cmap=pyplot.get_cmap('gray'))
# show the figure
pyplot.show()A execução do exemplo carrega o conjunto de dados MNIST e, em seguida, resume o treinamento padrão e os conjuntos de dados de teste.
Train: X=(60000, 28, 28), y=(60000,)
Test: X=(10000, 28, 28), y=(10000,)Um gráfico é então criado mostrando uma grade de exemplos de imagens manuscritas no conjunto de dados de treinamento.
Gráfico de dígitos manuscritos do conjunto de dados MNIST
Podemos treinar um modelo CNN para classificar as imagens no conjunto de dados MNIST.
Observe que as imagens são matrizes de dados de pixel em tons de cinza; portanto, devemos adicionar uma dimensão de canal aos dados antes de podermos usar as imagens como entrada para o modelo. A razão é que os modelos CNN esperam imagens no formato canais-último , ou seja, cada exemplo para que a rede tenha as dimensões [linhas, colunas, canais], onde os canais representam os canais de cores dos dados da imagem.
Também é uma boa ideia dimensionar os valores de pixel do intervalo padrão de 0-255 a 0-1 ao treinar um CNN. Para obter mais informações sobre como dimensionar valores de pixel.
O exemplo completo de ajuste e avaliação de um modelo CNN no conjunto de dados MNIST está listado abaixo.
# example of a cnn for image classification
from numpy import asarray
from numpy import unique
from numpy import argmax
from tensorflow.keras.datasets.mnist import load_data
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import MaxPool2D
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Dropout
# load dataset
(x_train, y_train), (x_test, y_test) = load_data()
# reshape data to have a single channel
x_train = x_train.reshape((x_train.shape[0], x_train.shape[1], x_train.shape[2], 1))
x_test = x_test.reshape((x_test.shape[0], x_test.shape[1], x_test.shape[2], 1))
# determine the shape of the input images
in_shape = x_train.shape[1:]
# determine the number of classes
n_classes = len(unique(y_train))
print(in_shape, n_classes)
# normalize pixel values
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# define model
model = Sequential()
model.add(Conv2D(32, (3,3), activation='relu', kernel_initializer='he_uniform', input_shape=in_shape))
model.add(MaxPool2D((2, 2)))
model.add(Flatten())
model.add(Dense(100, activation='relu', kernel_initializer='he_uniform'))
model.add(Dropout(0.5))
model.add(Dense(n_classes, activation='softmax'))
# define loss and optimizer
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# fit the model
model.fit(x_train, y_train, epochs=10, batch_size=128, verbose=0)
# evaluate the model
loss, acc = model.evaluate(x_test, y_test, verbose=0)
print('Accuracy: %.3f' % acc)
# make a prediction
image = x_train[0]
yhat = model.predict(asarray([image]))
print('Predicted: class=%d' % argmax(yhat))Executar o exemplo primeiro relata a forma do conjunto de dados, depois ajusta o modelo e o avalia no conjunto de dados de teste. Finalmente, é feita uma previsão para uma única imagem.
Nota : Seus resultados podem variar devido à natureza estocástica do algoritmo ou procedimento de avaliação, ou diferenças na precisão numérica. Considere executar o exemplo algumas vezes e compare o resultado médio.
Quais resultados você conseguiu? Você pode mudar o modelo para fazer melhor?
Publique suas descobertas nos comentários abaixo.
Primeiro, a forma de cada imagem é relatada junto com o número de classes; podemos ver que cada imagem tem 28 × 28 pixels e há 10 classes como esperávamos.
Nesse caso, podemos ver que o modelo alcançou uma precisão de classificação de cerca de 98 por cento no conjunto de dados de teste. Podemos então ver que o modelo previu a classe 5 para a primeira imagem do conjunto de treinamento.
(28, 28, 1) 10
Accuracy: 0.987
Predicted: class=53.3 Desenvolver Modelos de Rede Neural Recorrente
Redes Neurais Recorrentes, ou RNNs, são projetadas para operar em sequências de dados.
Eles provaram ser muito eficazes para problemas de processamento de linguagem natural em que sequências de texto são fornecidas como entrada para o modelo. Os RNNs também obtiveram algum sucesso modesto para previsão de séries temporais e reconhecimento de voz.
O tipo mais popular de RNN é a rede Long Short-Term Memory, ou LSTM. Os LSTMs podem ser usados em um modelo para aceitar uma sequência de dados de entrada e fazer uma previsão, como atribuir um rótulo de classe ou prever um valor numérico como o próximo valor ou valores na sequência.
Usaremos o conjunto de dados de vendas de carros para demonstrar um LSTM RNN para previsão de série temporal univariada.
Esse problema envolve prever o número de vendas de carros por mês.
O conjunto de dados será baixado automaticamente usando o Pandas, mas você pode aprender mais sobre isso aqui.
- Conjunto de dados de vendas de automóveis (csv) .
- Descrição do conjunto de dados de vendas de automóveis (csv) .
Estruturaremos o problema para obter uma janela dos últimos cinco meses de dados para prever os dados do mês atual.
Para conseguir isso, definiremos uma nova função chamada split_sequence () que dividirá a sequência de entrada em janelas de dados apropriadas para ajustar um modelo de aprendizado supervisionado, como um LSTM.
Por exemplo, se a sequência foi:
| 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 |
Em seguida, as amostras para treinar o modelo serão semelhantes a:
Input Output
1, 2, 3, 4, 5 6
2, 3, 4, 5, 6 7
3, 4, 5, 6, 7 8
...
1
2
3
4
5
Input Output
1, 2, 3, 4, 5 6
2, 3, 4, 5, 6 7
3, 4, 5, 6, 7 8
...Usaremos os últimos 12 meses de dados como o conjunto de dados de teste.
Os LSTMs esperam que cada amostra no conjunto de dados tenha duas dimensões; o primeiro é o número de intervalos de tempo (neste caso é 5), e o segundo é o número de observações por intervalo de tempo (neste caso, é 1).
Por ser um problema do tipo regressão, usaremos uma função de ativação linear (sem
função de ativação ) na camada de saída e otimizaremos a função de perda de erro quadrático médio. Também avaliaremos o modelo usando a métrica do erro absoluto médio (MAE).
O exemplo completo de ajuste e avaliação de um LSTM para um problema de previsão de série temporal univariada está listado abaixo.
# lstm for time series forecasting
from numpy import sqrt
from numpy import asarray
from pandas import read_csv
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
# split a univariate sequence into samples
def split_sequence(sequence, n_steps):
X, y = list(), list()
for i in range(len(sequence)):
# find the end of this pattern
end_ix = i + n_steps
# check if we are beyond the sequence
if end_ix > len(sequence)-1:
break
# gather input and output parts of the pattern
seq_x, seq_y = sequence[i:end_ix], sequence[end_ix]
X.append(seq_x)
y.append(seq_y)
return asarray(X), asarray(y)
# load the dataset
path = 'https://raw.githubusercontent.com/jbrownlee/Datasets/master/monthly-car-sales.csv'
df = read_csv(path, header=0, index_col=0, squeeze=True)
# retrieve the values
values = df.values.astype('float32')
# specify the window size
n_steps = 5
# split into samples
X, y = split_sequence(values, n_steps)
# reshape into [samples, timesteps, features]
X = X.reshape((X.shape[0], X.shape[1], 1))
# split into train/test
n_test = 12
X_train, X_test, y_train, y_test = X[:-n_test], X[-n_test:], y[:-n_test], y[-n_test:]
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
# define model
model = Sequential()
model.add(LSTM(100, activation='relu', kernel_initializer='he_normal', input_shape=(n_steps,1)))
model.add(Dense(50, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(50, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(1))
# compile the model
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
# fit the model
model.fit(X_train, y_train, epochs=350, batch_size=32, verbose=2, validation_data=(X_test, y_test))
# evaluate the model
mse, mae = model.evaluate(X_test, y_test, verbose=0)
print('MSE: %.3f, RMSE: %.3f, MAE: %.3f' % (mse, sqrt(mse), mae))
# make a prediction
row = asarray([18024.0, 16722.0, 14385.0, 21342.0, 17180.0]).reshape((1, n_steps, 1))
yhat = model.predict(row)
print('Predicted: %.3f' % (yhat))Executar o exemplo primeiro relata a forma do conjunto de dados, depois ajusta o modelo e o avalia no conjunto de dados de teste. Finalmente, uma previsão é feita para um único exemplo.
Nota : Seus resultados podem variar devido à natureza estocástica do algoritmo ou procedimento de avaliação, ou diferenças na precisão numérica. Considere executar o exemplo algumas vezes e compare o resultado médio.
Quais resultados você conseguiu? Você pode mudar o modelo para fazer melhor?
Publique suas descobertas nos comentários abaixo.
Primeiro, a forma do trem e os conjuntos de dados de teste são exibidos, confirmando que os últimos 12 exemplos são usados para avaliação do modelo.
Nesse caso, o modelo atingiu um MAE de cerca de 2.800 e previu o próximo valor na sequência do conjunto de testes como 13.199, onde o valor esperado é 14.577 (bem próximo).
(91, 5, 1) (12, 5, 1) (91,) (12,)
MSE: 12755421.000, RMSE: 3571.473, MAE: 2856.084
Predicted: 13199.325Nota : é uma boa prática dimensionar e tornar a série estacionária os dados antes de ajustar o modelo. Eu recomendo isso como uma extensão para obter um melhor desempenho. Para obter mais informações sobre como preparar dados de série temporal para modelagem.
4. Como usar os recursos avançados do modelo
Nesta seção, você descobrirá como usar alguns dos recursos de modelo um pouco mais avançados, como revisar curvas de aprendizado e salvar modelos para uso posterior.
4.1 Como visualizar um modelo de aprendizado profundo
A arquitetura de modelos de aprendizado profundo pode rapidamente se tornar grande e complexa.
Como tal, é importante ter uma ideia clara das conexões e do fluxo de dados em seu modelo. Isso é especialmente importante se você estiver usando a API funcional para garantir que realmente conectou as camadas do modelo da maneira desejada.
Existem duas ferramentas que você pode usar para visualizar seu modelo: uma descrição de texto e um gráfico.
Descrição do Texto do Modelo
Uma descrição de texto de seu modelo pode ser exibida chamando a função summary () em seu modelo.
O exemplo abaixo define um pequeno modelo com três camadas e, em seguida, resume a estrutura.
# example of summarizing a model
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
# define model
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(8,)))
model.add(Dense(8, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(1, activation='sigmoid'))
# summarize the model
model.summary()Executar o exemplo imprime um resumo de cada camada, bem como um resumo total.
Este é um diagnóstico inestimável para verificar as formas de saída e o número de parâmetros (pesos) em seu modelo.
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 10) 90
_________________________________________________________________
dense_1 (Dense) (None, 8) 88
_________________________________________________________________
dense_2 (Dense) (None, 1) 9
=================================================================
Total params: 187
Trainable params: 187
Non-trainable params: 0
_________________________________________________________________Gráfico da Arquitetura do Modelo
Você pode criar um gráfico de seu modelo chamando a função plot_model () .
Isso criará um arquivo de imagem que contém uma caixa e um diagrama de linha das camadas em seu modelo.
O exemplo abaixo cria um pequeno modelo de três camadas e salva um gráfico da arquitetura do modelo em ‘ model.png ‘ que inclui formas de entrada e saída.
# example of plotting a model
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.utils import plot_model
# define model
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(8,)))
model.add(Dense(8, activation='relu', kernel_initializer='he_normal'))
model.add(Dense(1, activation='sigmoid'))
# summarize the model
plot_model(model, 'model.png', show_shapes=True)A execução do exemplo cria um gráfico do modelo mostrando uma caixa para cada camada com informações de forma e setas que conectam as camadas, mostrando o fluxo de dados pela rede.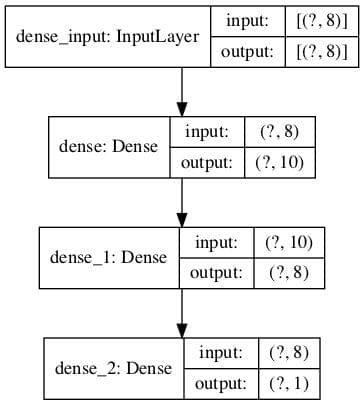
Trama da arquitetura de rede neural
4.2 Como traçar curvas de aprendizagem do modelo
As curvas de aprendizado são um gráfico do desempenho do modelo de rede neural ao longo do tempo, como calculado ao final de cada período de treinamento.
Gráficos de curvas de aprendizado fornecem insights sobre a dinâmica de aprendizado do modelo, como se o modelo está aprendendo bem, se está subjugando o conjunto de dados de treinamento ou superdimensionando o conjunto de dados de treinamento.
Para obter uma introdução suave às curvas de aprendizado e como usá-las para diagnosticar a dinâmica de aprendizado de modelos.
Você pode criar facilmente curvas de aprendizado para seus modelos de aprendizado profundo.
Primeiro, você deve atualizar sua chamada para a função de ajuste para incluir referência a um conjunto de dados de validação . Esta é uma parte do conjunto de treinamento não usada para ajustar o modelo e, em vez disso, é usada para avaliar o desempenho do modelo durante o treinamento.
Você pode dividir os dados manualmente e especificar o argumento validation_data ou pode usar o argumento validation_split e especificar uma divisão de porcentagem do conjunto de dados de treinamento e permitir que a API execute a divisão para você. O último é mais simples por enquanto.
A função de ajuste retornará um objeto de histórico que contém um traço de métricas de desempenho registradas no final de cada período de treinamento. Isso inclui a função de perda escolhida e cada métrica configurada, como precisão, e cada perda e métrica é calculada para os conjuntos de dados de treinamento e validação.
Uma curva de aprendizado é um gráfico da perda no conjunto de dados de treinamento e no conjunto de dados de validação. Podemos criar este gráfico a partir do objeto de histórico usando a biblioteca Matplotlib .
O exemplo abaixo se ajusta a uma pequena rede neural em um problema de classificação binária sintética. Uma divisão de validação de 30 por cento é usada para avaliar o modelo durante o treinamento e a perda de entropia cruzada no trem e os conjuntos de dados de validação são então representados graficamente usando um gráfico de linha.
# example of plotting learning curves
from sklearn.datasets import make_classification
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
from matplotlib import pyplot
# create the dataset
X, y = make_classification(n_samples=1000, n_classes=2, random_state=1)
# determine the number of input features
n_features = X.shape[1]
# define model
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(1, activation='sigmoid'))
# compile the model
sgd = SGD(learning_rate=0.001, momentum=0.8)
model.compile(optimizer=sgd, loss='binary_crossentropy')
# fit the model
history = model.fit(X, y, epochs=100, batch_size=32, verbose=0, validation_split=0.3)
# plot learning curves
pyplot.title('Learning Curves')
pyplot.xlabel('Epoch')
pyplot.ylabel('Cross Entropy')
pyplot.plot(history.history['loss'], label='train')
pyplot.plot(history.history['val_loss'], label='val')
pyplot.legend()
pyplot.show()A execução do exemplo ajusta o modelo ao conjunto de dados. No final da execução, o objeto de histórico é retornado e usado como base para a criação do gráfico de linha.
A perda de entropia cruzada para o conjunto de dados de treinamento é acessada por meio da chave ‘ perda ‘ e a perda no conjunto de dados de validação é acessada por meio da chave ‘ val_loss ‘ no atributo de histórico do objeto de histórico.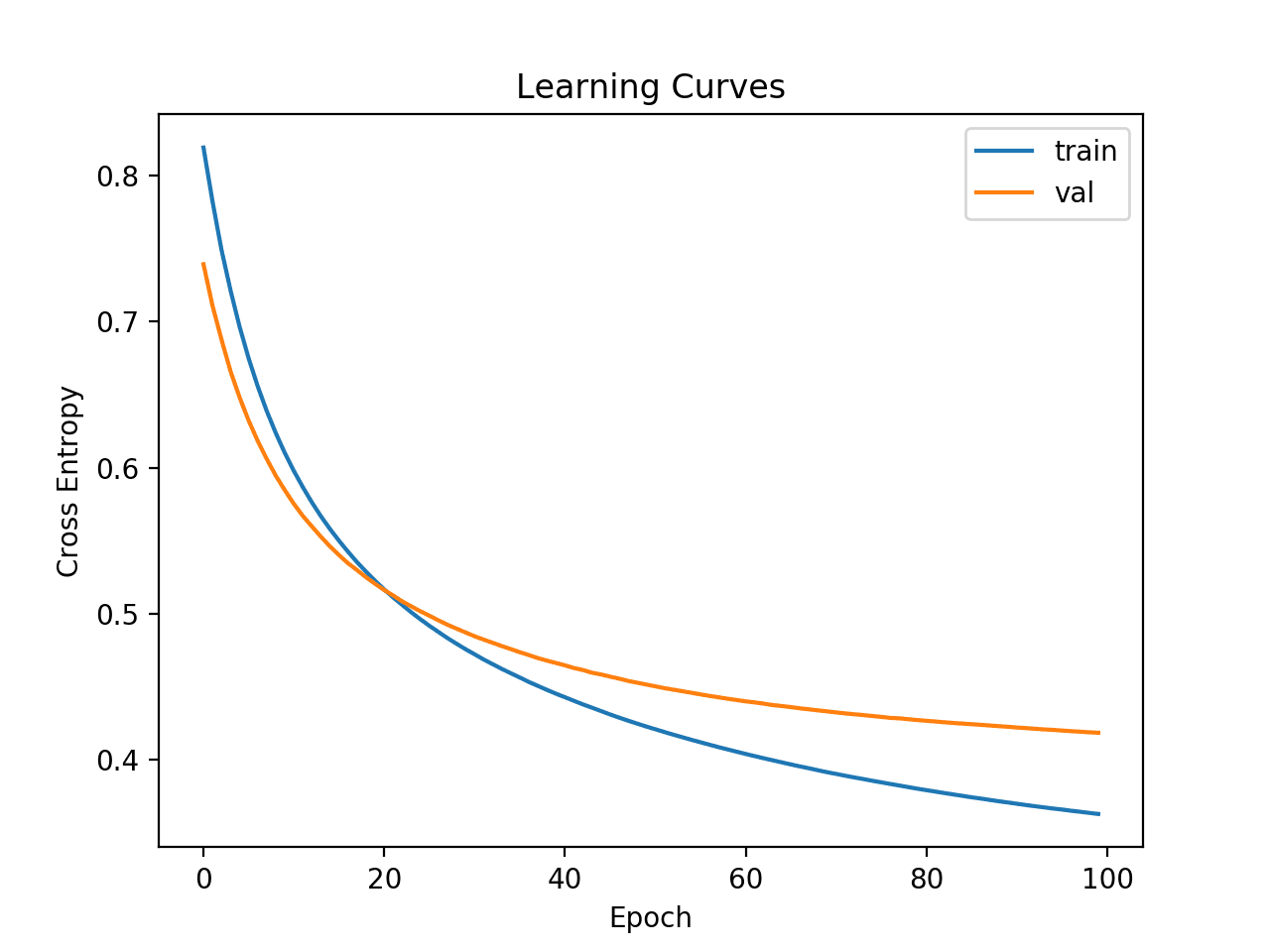
Curvas de aprendizagem de perda de entropia cruzada para um modelo de aprendizado profundo
4.3 Como salvar e carregar seu modelo
Treinar e avaliar modelos é ótimo, mas podemos querer usar um modelo mais tarde, sem treiná-lo novamente a cada vez.
Isso pode ser obtido salvando o modelo em um arquivo e, posteriormente, carregando-o e usando-o para fazer previsões.
Isso pode ser obtido usando a função save () no modelo para salvar o modelo. Ele pode ser carregado posteriormente usando a função load_model () .
O modelo é salvo no formato H5, um formato de armazenamento de array eficiente. Dessa forma, você deve garantir que a biblioteca h5py esteja instalada em sua estação de trabalho. Isso pode ser feito usando pip ; por exemplo:
| 1 | pip install h5py |
O exemplo abaixo se ajusta a um modelo simples em um problema de classificação binária sintética e salva o arquivo de modelo.
# example of saving a fit model
from sklearn.datasets import make_classification
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import SGD
# create the dataset
X, y = make_classification(n_samples=1000, n_features=4, n_classes=2, random_state=1)
# determine the number of input features
n_features = X.shape[1]
# define model
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(1, activation='sigmoid'))
# compile the model
sgd = SGD(learning_rate=0.001, momentum=0.8)
model.compile(optimizer=sgd, loss='binary_crossentropy')
# fit the model
model.fit(X, y, epochs=100, batch_size=32, verbose=0, validation_split=0.3)
# save model to file
model.save('model.h5')Executar o exemplo ajusta o modelo e o salva em um arquivo com o nome ‘ model.h5 ‘.
Podemos então carregar o modelo e usá-lo para fazer uma previsão, continuar treinando ou fazer o que quisermos com ele.
O exemplo abaixo carrega o modelo e o usa para fazer uma previsão.
# example of loading a saved model
from sklearn.datasets import make_classification
from tensorflow.keras.models import load_model
# create the dataset
X, y = make_classification(n_samples=1000, n_features=4, n_classes=2, random_state=1)
# load the model from file
model = load_model('model.h5')
# make a prediction
row = [1.91518414, 1.14995454, -1.52847073, 0.79430654]
yhat = model.predict([row])
print('Predicted: %.3f' % yhat[0])
A execução do exemplo carrega a imagem do arquivo, a usa para fazer uma previsão em uma nova linha de dados e imprime o resultado.
| Predicted: 0.831 |
5. Como obter um melhor desempenho do modelo
Nesta seção, você descobrirá algumas das técnicas que pode usar para melhorar o desempenho de seus modelos de aprendizado profundo.
Uma grande parte da melhoria do desempenho do aprendizado profundo envolve evitar overfitting, desacelerando o processo de aprendizado ou interrompendo o processo de aprendizado no momento certo.
5.1 Como reduzir o sobreajuste com abandono
O dropout é um método de regularização inteligente que reduz o overfitting do conjunto de dados de treinamento e torna o modelo mais robusto.
Isso é obtido durante o treinamento, onde algum número de saídas de camada são ignoradas aleatoriamente ou “ descartadas ”. Isso tem o efeito de fazer com que a camada pareça – e seja tratada como – uma camada com um número diferente de nós e conectividade com a camada anterior.
O dropout tem o efeito de tornar o processo de treinamento ruidoso, forçando os nós de uma camada a assumir probabilisticamente mais ou menos responsabilidade pelas entradas.
Você pode adicionar dropout aos seus modelos como uma nova camada antes da camada em que deseja que as conexões de entrada sejam retiradas.
Isso envolve a adição de uma camada chamada Dropout () que recebe um argumento que especifica a probabilidade de cada saída da anterior cair. Por exemplo, 0,4 significa que 40 por cento das entradas serão descartadas a cada atualização do modelo.
Você pode adicionar camadas de exclusão em modelos MLP, CNN e RNN, embora também existam versões especializadas de exclusão para uso com modelos CNN e RNN que você também pode querer explorar.
O exemplo abaixo se ajusta a um pequeno modelo de rede neural em um problema de classificação binária sintética.
Uma camada de eliminação com 50 por cento de eliminação é inserida entre a primeira camada oculta e a camada de saída.
# example of using dropout
from sklearn.datasets import make_classification
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Dropout
from matplotlib import pyplot
# create the dataset
X, y = make_classification(n_samples=1000, n_classes=2, random_state=1)
# determine the number of input features
n_features = X.shape[1]
# define model
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy')
# fit the model
model.fit(X, y, epochs=100, batch_size=32, verbose=0)
5.2 Como acelerar o treinamento com normalização em lote
A escala e a distribuição de entradas para uma camada podem impactar muito a facilidade ou rapidez com que essa camada pode ser treinada.
Geralmente é por isso que é uma boa ideia dimensionar os dados de entrada antes de modelá-los com um modelo de rede neural.
A normalização em lote é uma técnica para treinar redes neurais muito profundas que padroniza as entradas para uma camada para cada minilote. Isso tem o efeito de estabilizar o processo de aprendizagem e reduzir drasticamente o número de períodos de treinamento necessários para treinar redes profundas.
Você pode usar a normalização em lote em sua rede adicionando uma camada de normalização em lote antes da camada que deseja ter entradas padronizadas. Você pode usar a normalização em lote com modelos MLP, CNN e RNN.
Isso pode ser obtido adicionando a camada BatchNormalization diretamente .
O exemplo abaixo define uma pequena rede MLP para um problema de previsão de classificação binária com uma camada de normalização em lote entre a primeira camada oculta e a camada de saída.
# example of using batch normalization
from sklearn.datasets import make_classification
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import BatchNormalization
from matplotlib import pyplot
# create the dataset
X, y = make_classification(n_samples=1000, n_classes=2, random_state=1)
# determine the number of input features
n_features = X.shape[1]
# define model
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(BatchNormalization())
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy')
# fit the model
model.fit(X, y, epochs=100, batch_size=32, verbose=0)Além disso, tf.keras tem uma variedade de outras camadas de normalização que você pode querer explorar; Vejo:
5.3 Como interromper o treinamento no momento certo com parada precoce
As redes neurais são um desafio para treinar.
Muito pouco treinamento e o modelo é insuficiente; muito treinamento e o modelo supera o conjunto de dados de treinamento. Ambos os casos resultam em um modelo menos eficaz do que poderia ser.
Uma abordagem para resolver esse problema é usar a parada antecipada. Isso envolve o monitoramento da perda no conjunto de dados de treinamento e um conjunto de dados de validação (um subconjunto do conjunto de treinamento não usado para ajustar o modelo). Assim que a perda do conjunto de validação começar a mostrar sinais de sobreajuste, o processo de treinamento pode ser interrompido.
A parada antecipada pode ser usada com seu modelo, primeiro garantindo que você tenha um conjunto de dados de validação . Você pode definir o conjunto de dados de validação manualmente por meio do argumento validation_data para a função fit () , ou você pode usar o validation_split e especificar a quantidade de conjunto de dados de treinamento para reter para validação.
Você pode então definir um EarlyStopping e instruí-lo sobre qual medida de desempenho monitorar, como ‘ val_loss ‘ para perda no conjunto de dados de validação e o número de épocas para o overfitting observado antes de agir, por exemplo, 5.
Esse retorno de chamada de EarlyStopping configurado pode então ser fornecido à função fit () por meio do argumento “ callbacks ” que obtém uma lista de callbacks.
Isso permite que você defina o número de épocas como um grande número e tenha a certeza de que o treinamento terminará assim que o modelo começar a ajustar. Você também pode querer criar uma curva de aprendizado para descobrir mais insights sobre a dinâmica de aprendizado da corrida e quando o treinamento foi interrompido.
O exemplo a seguir demonstra uma pequena rede neural em um problema de classificação binária sintética que usa a parada antecipada para interromper o treinamento assim que o modelo começa a superajustar (após cerca de 50 épocas).
# example of using early stopping
from sklearn.datasets import make_classification
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.callbacks import EarlyStopping
# create the dataset
X, y = make_classification(n_samples=1000, n_classes=2, random_state=1)
# determine the number of input features
n_features = X.shape[1]
# define model
model = Sequential()
model.add(Dense(10, activation='relu', kernel_initializer='he_normal', input_shape=(n_features,)))
model.add(Dense(1, activation='sigmoid'))
# compile the model
model.compile(optimizer='adam', loss='binary_crossentropy')
# configure early stopping
es = EarlyStopping(monitor='val_loss', patience=5)
# fit the model
history = model.fit(X, y, epochs=200, batch_size=32, verbose=0, validation_split=0.3, callbacks=[es]A API tf.keras fornece vários retornos de chamada que você pode querer explorar; Você pode aprender mais aqui:
Resumo
Neste tutorial, você descobriu um guia passo a passo para desenvolver modelos de aprendizado profundo no TensorFlow usando a API tf.keras.
Especificamente, você aprendeu:
- A diferença entre Keras e tf.keras e como instalar e confirmar se o TensorFlow está funcionando.
- O ciclo de vida de 5 etapas dos modelos tf.keras e como usar as APIs sequenciais e funcionais.
- Como desenvolver modelos MLP, CNN e RNN com tf.keras para regressão, classificação e previsão de séries temporais.
- Como usar os recursos avançados da API tf.keras para inspecionar e diagnosticar seu modelo.
- Como melhorar o desempenho do seu modelo tf.keras reduzindo o overfitting e acelerando o treinamento.
Você tem alguma pergunta?
Tire suas dúvidas nos comentários abaixo e farei o possível para responder.
Aprenda mais sobre python clique aqui