
Data Lakes com Parquet
Este artigo é o primeiro de uma série chamada ‘Foca no data lake’, na qual apresentaremos várias tecnologias para execução de consultas analíticas em data lakes na AWS .
Indo direto ao assunto existem muitas tecnologias disponíveis que você pode usar para consultar big data na AWS, cada uma com seus prós e contras. Não pretendemos cobrir todos eles: nesta série falaremos sobre as tecnologias nativas da AWS, que são Athena e Redshift , bem como Snowflake , Databricks e Dremio . Também poderíamos adicionar Cloudera à lista.
Observe que esta série de blogs não pretende ser uma comparação dessas tecnologias, mas sim ajudá-lo com as primeiras etapas que você pode dar com elas, mostrando como carregar e consultar dados usando um conjunto de dados conhecido e comum e um conjunto de dados conhecido e comum conjunto de consultas. Se você tiver alguma dúvida sobre qual tecnologia é a mais adequada para o seu caso, entre em contato conosco e teremos o maior prazer em ajudá-lo e orientá-lo ao longo de sua jornada.
Mas antes de analisar as várias opções disponíveis para consultar data lakes na AWS, queremos abordar este artigo inicial do blog para discutir um tópico importante sobre data lakes, que é o formato e os mecanismos de otimização usados neles, especialmente quando os dados vão ser utilizado para fins analíticos; o escopo deste blog é discutir formatos de data lake e mecanismos de otimização.
Também apresentaremos o conceito de data lakehouse, que está ganhando bastante força e está muito relacionado à ideia de otimizar data lakes para consulta. Por fim, apresentaremos um exemplo de como aplicar uma abordagem comum de otimização de data lake na AWS; mais precisamente, mostraremos um exemplo de como transformar um conjunto de dados no formato CSV para o formato Apache Parquet na AWS e como particioná-lo. Essas versões do conjunto de dados, o CSV e o Parquet (não particionado e particionado), serão usadas como ponto de partida em futuros blogs, onde veremos como usar essas diferentes tecnologias para consultar data lakes.
Otimizações do Data Lake
Os data lakes são usados para armazenar dados grandes e variados provenientes de várias fontes de dados. Muitas dessas fontes de dados geram dados em formatos brutos, como CSV ou JSON. No entanto, usar esses formatos brutos para fins analíticos, quando os dados ficam relativamente grandes, produz resultados ruins. Embora seja tecnicamente possível usar os formatos brutos diretamente para fins analíticos, uma abordagem comum para realizar a análise de Datas lakes (dados em lagos) é transformar os dados em um formato como o Parquet, que tem melhor desempenho.
Apache Parquet
Apache Parquet é um formato de arquivo de código aberto que armazena dados em um formato colunar, compressível usando esquemas de codificação eficientes e armazena metadados em um cabeçalho. Esses vários mecanismos oferecem desempenhos de leitura muito melhores em comparação ao uso de formatos brutos, o que é crítico ao usar os dados para fins analíticos. Além disso, um arquivo Parquet tem cerca de um terço do tamanho de um arquivo CSV, o que economiza custos de armazenamento e reduz a quantidade de dados lidos, tornando a leitura de Parquets muito mais rápida do que os formatos brutos.
Particionamento
Além de usar formatos de arquivo otimizados como Parquet, outra abordagem comum para otimização adicional é particionar os dados (os dados são armazenados em pastas diferentes com base em um valor de coluna – ou em várias colunas) que permitirá a remoção de partições ao consultar os dados.
Basicamente, as pastas são armazenadas em ordem, de modo que o mecanismo de consulta (seja qual for) lê o nome da pasta para saber se os valores correspondem aos desejados. Dessa forma, apenas as pastas desejadas são acessadas e todo o conteúdo é lido, enquanto as demais são ignoradas. Além disso, à medida que é ordenado, uma vez que o valor atual que está sendo verificado é maior que o valor máximo desejado, o processo termina.
Formatos Alternativos e Mecanismos de Otimização
Observe que existem outros formatos ( ORC , Delta , etc.) e outros mecanismos de otimização que podem ser aplicados (clustering, por exemplo) em vez de, ou complementares, Parquet e particionamento. Não hesite em nos contatar para discutir qual combinação é a melhor para o seu caso.
Data Lakehouses
Quando entramos no assunto de otimização de data lake, devemos mencionar um conceito de tendência: data lakehouses. Como o nome sugere, esse conceito, ou termo abrangente, define uma plataforma que combina o alcance de armazenamento do data lake (armazene o quanto quiser) com o poder analítico do data warehouse.
Não parece haver uma definição comum de exatamente o que é um data lakehouse, já que cada fornecedor tem sua própria definição (geralmente destacando os aspectos em que cada tecnologia brilha). Confira as definições das diferentes tecnologias que abordaremos nesta série em inglês: AWS , Snowflake , Databricks e Dremio , e você verá o amplo espectro de definições dessa nova palavra da moda.
Exemplo de otimização do Data Lake
Agora que terminamos as introduções, nas seções a seguir vamos demonstrar como podemos otimizar um data lake por meio de um conjunto de dados de exemplo. Vamos primeiro gerar o conjunto de dados em CSVs e depois convertê-los em Parquet sem e finalmente com partições, terminando assim com 3 versões diferentes do conjunto de dados.
Conjunto de dados de exemplo
O conjunto de dados que usaremos nesta série de blogs é o famoso conjunto de dados de benchmark TPC-H . Este conjunto de dados é composto por 8 tabelas e emula qualquer indústria que venda ou distribua um produto em todo o mundo, armazenando dados sobre clientes, pedidos, fornecedores, etc. Você pode ver o modelo de dados abaixo:
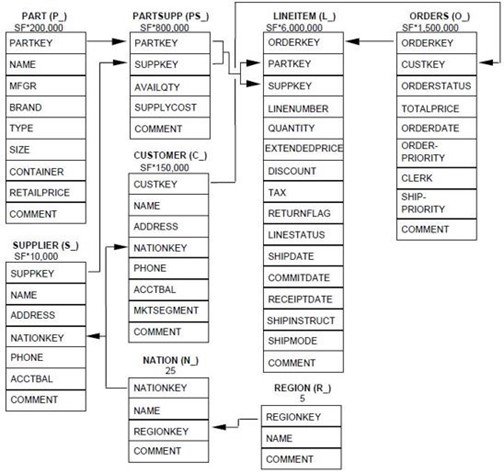
Os números abaixo dos nomes das tabelas representam o número de linhas em cada tabela de forma proporcional. Podemos ver que LINEITEM e ORDERS são tabelas bastante grandes em comparação com outras, como REGION ou NATION.
Neste artigo, vamos gerar 3 versões diferentes do mesmo conjunto de dados em formatos diferentes, primeiro gerando os dados brutos (CSV), e depois convertendo-os em arquivos Parquet sem e finalmente com partições (somente para as maiores tabelas –LINEITEM e ORDERS). Nas seções a seguir, explicaremos como geramos os dados brutos e os arquivos Parquet não particionados e particionados.
Nas próximas postagens do blog desta série, usaremos vários mecanismos de consulta de data lake para consultar as 3 versões do conjunto de dados e conectaremos uma ferramenta de relatório como o Tableau a cada mecanismo para realizar algumas operações também – para ser específico , vamos realizar 10 consultas do documento oficial de especificação TPC-H .
Gerando o conjunto de dados
A geração do dataset foi um passo bastante simples pois utilizamos a ferramenta tpc-dbgen que gera automaticamente o dataset com 8 pastas, 1 por tabela, com um número especificado de CSVs em cada uma. Especificamente, criamos um total de 100 GB de CSVs, com 80 CSVs para cada tabela para dar mais realismo (as tabelas pequenas, como NATION, possuem apenas um único arquivo).
Convertendo CSV para Parquet e particionando o conjunto de dados
Depois que todos os CSVs forem colocados no bucket do S3, há dois serviços diferentes da AWS para convertê-los em Parquet:
Ambos os serviços têm seus prós e contras, e vamos explicá-los abaixo:
Athena
A primeira opção que vamos explicar é a mais barata e rápida para criar arquivos Parquet. O Athena é um serviço de consulta sem servidor, sem necessidade de administração, que permite que os usuários consultem dados de vários serviços da AWS, como o S3, e você é cobrado pela quantidade de dados verificados. Também é possível criar bancos de dados (contêineres de tabela) e tabelas usando o Glue Data Catalogs, que é gratuito, pois o Athena não está faturando declarações DDL. Verifique os preços do Athena para mais detalhes. Lembre-se de que você pode armazenar até um milhão de objetos no Catálogo de dados do Glue gratuitamente – consulte a página de preços do Glue .
Além das consultas regulares, também podemos criar tabelas a partir dos resultados da consulta (CTAS). Essa funcionalidade permite executar uma instrução para criar arquivos Parquet a partir de CSVs e também criar automaticamente sua tabela de Catálogo de Dados.
Primeiro, para ler o CSV, tivemos que criar um Catálogo de Dados apontando para cada pasta de tabela no S3. Primeiro criamos um banco de dados e todas as tabelas, mas para simplificar vamos mostrar apenas a tabela de ORDERS. Embora você possa criar a tabela e o banco de dados diretamente na página do Catálogo de Dados do Glue, executamos este código manualmente no Athena:
CREATE database IF NOT EXISTS tpc_csv;
CREATE external TABLE tpc_csv.orders(
o_orderkey BIGINT,
o_custkey BIGINT,
o_orderstatus varchar(1),
o_totalprice float,
o_orderdate date,
o_orderpriority varchar(15),
o_clerk varchar(15),
o_shippriority int,
o_comment varchar(79)
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
STORED AS textfile
LOCATION 's3://your_s3_bucket/tpc-h-csv/orders/';
Basicamente, definimos cada tipo de atributo, indicamos a localização no S3 e especificamos o separador, que é ‘|’. Isso ocorre porque o dbgen gera TSVs, não CSVs, mas não há diferença, exceto o separador.
Depois que todas as tabelas foram criadas no Catálogo, a instrução SELECT AS pode criar facilmente o arquivo Parquet sem partições.
CREATE database IF NOT EXISTS tpc_Parquet;
CREATE TABLE tpc_Parquet.orders
WITH (
format = 'Parquet',
Parquet_compression = 'SNAPPY',
external_location = 's3://your_s3_bucket/tpc-h-Parquet/orders/'
) AS SELECT * FROM tpc_csv.orders;
Como você pode ver, com algumas linhas de código, criamos os arquivos Parquet no S3 e também as ordens da tabela Data Catalog no banco de dados tpc_Parquet a partir do resultado de selecionar tudo do banco de dados tpc_csv .
Particionando com Athena
Conforme discutido acima, embora a conversão para Parquet seja uma grande melhoria para a consulta, também é possível otimizá-la ainda mais particionando os dados, permitindo a remoção de dados desnecessários quando as consultas são executadas. Observe que o particionamento só faz sentido para tabelas grandes. A chave, é claro, é selecionar colunas de particionamento adequadas.
No nosso caso, examinamos as consultas definidas na especificação TPC-H e identificamos facilmente a coluna l_shipdate da tabela de itens de linha e a coluna o_orderadate dos ORDERS como as colunas de particionamento mais adequadas. Essencialmente, analisamos quais colunas foram encontradas com mais frequência nas instruções de filtragem das consultas; uma vez identificada a coluna de particionamento, o código para criar uma tabela particionada a partir de outra tabela é (exemplo mostrado apenas para a tabela de ORDERS):
CREATE TABLE tpc_Parquet.orders
WITH (
format = 'Parquet',
Parquet_compression = 'SNAPPY',
partitioned_by = ARRAY['o_orderdate'],
external_location = 's3://your_s3_bucket/tpc-h-Parquet/orders/'
) AS SELECT * FROM tpc_csv.orders;Observe o ARRAY no partitioned_by , que é obrigatório mesmo se você estiver usando uma única chave de partição. Depois de criar a tabela particionada, ela ainda não poderá ser consultada até que você execute o comando para verificar o sistema de arquivos em busca de partições compatíveis com Hive:
MSCK REPAIR TABLE tpc_Parquet.orders No entanto, o Athena CTAS tem uma limitação: só pode criar um máximo de 100 partições por consulta. No nosso caso, é uma grande limitação porque temos 8 anos de dados diários e queremos particionar por data em nível de dia.
Dito isso, há uma solução explicada na documentação da AWS usando INSERT INTO para “anexar” as partições. No entanto, essa opção pode precisar do desenvolvimento de um script para automatizar e facilitar o processo, o que pode ser tedioso. Pode ser uma boa ideia considerar o Glue para criar Parquets com mais de 100 partições em uma única execução.
Cola
O AWS Glue é um serviço ETL sem servidor no qual você pode criar catálogos, transformar e carregar dados usando tarefas do Spark (PySpark, especificamente). Ele também fornece uma estrutura sobre o Spark chamada GlueContext que simplifica o desenvolvimento do trabalho. Além disso, a AWS incorporou recentemente o Glue Studio , uma interface do usuário para criar trabalhos do Glue sem codificação, arrastando e soltando caixas para aplicar algumas configurações. O Glue Studio cria automaticamente o código GlueContext a partir do fluxo visual e você pode revisá-lo antes de executá-lo.
Então, usamos o Glue e o Glue Studio para converter nosso CSV em Parquet e fazer o particionamento; embora tenhamos conseguido, encontramos alguns problemas que descreveremos abaixo para ajudar outras pessoas a tentarem o mesmo.
Primeiro tentamos o Glue Studio lendo diretamente do S3, em vez dos catálogos. No entanto, nenhum dos valores decimais pôde ser lido; todos foram definidos como nulos ou em branco. Isso foi corrigido quando mudamos para usar o catálogo como fonte, embora também tivéssemos que alternar para trabalhos regulares do Glue e editar o ApplyMapping onde poderíamos converter floats em decimal (isso é necessário devido ao decimal ser o tipo de dados flutuante padrão no Parquet) . Por fim, tentamos gravar e particionar os dados configurando corretamente a função write_dynamic_frame do GlueContext:
datasource = glueContext.create_dynamic_frame.from_catalog(database =
"tpc_csv", table_name = "orders", transformation_ctx = "datasource")
applymapping = ApplyMapping.apply(frame = datasource, mappings = [("o_orderkey", "long",
"o_orderkey", "long"), ("o_custkey", "long", "o_custkey", "long"), ("o_orderstatus", "string",
"o_orderstatus", "string"), ("o_totalprice", "float", "o_totalprice", "decimal"),
("o_orderdate", "date", "o_orderdate", "date"), ("o_orderpriority", "string",
"o_orderpriority", "string"), ("o_clerk", "string", "o_clerk", "string"),
("o_shippriority", "int", "o_shippriority", "int"), ("o_comment", "string", "o_comment",
"string")], transformation_ctx = "applymapping")
datasink = glueContext.write_dynamic_frame.from_options(frame = applymapping, connection_type
= "s3", connection_options = {"path": " s3://your_s3_bucket/tpc-h-Parquet/orders" ,
"partitionKeys": ["o_orderdate"]}, format = "Parquet", transformation_ctx = "datasink") No entanto, todas as partições estavam sendo criadas como __HIVE_DEFAULT_PARTITION__, o que significa que o campo usado para particionar é nulo. Ao investigar, percebemos que a classe ApplyMapping, que é usada para selecionar as colunas que você deseja usar, renomear colunas e para conversão de tipos, estava convertendo todos os valores de data para null quando estávamos selecionando apenas os campos sem nenhum mapeamento específico ( conversão para o mesmo nome e tipo de coluna).
Para corrigir isso, tivemos que usar o padrão PySpark DataFrame e suas operações. O código que usamos é:
datasource = glueContext.create_dynamic_frame.from_catalog (database =
"tpc_csv", table_name = "orders", transformation_ctx = "datasource")
df = datasource.toDF()
df = df.drop("col9")
df = df.withColumn("o_totalprice", col("o_totalprice").cast(DecimalType(18,2)))
df.show(10)
df.repartition(1,col("o_orderdate")).write.Parquet(s3://your_s3_bucket/tpc-h-
Parquet/orders', partitionBy=['o_orderdate']) Usamos o GlueContext para ler o catálogo e depois convertemos o Glue DynamicFrame em um PySpark DataFrame; em seguida, descartamos uma coluna extra e convertemos um campo decimal para DecimalType, porque o tipo nativo Parquet para números decimais é Decimal. Por fim, ao gravar os arquivos Parquet no S3 a partir do DataFrame, definimos a repartição como 1 porque a quantidade de dados gerados a cada dia não é superior a 100 MB, portanto, é mais rápido armazenar tudo em um único arquivo e também mais rápido de ler.
Observe que particionamos apenas as maiores tabelas (orders e lineitem).
A seguir
Com a abordagem discutida acima, criamos com sucesso essas três versões diferentes do mesmo conjunto de dados TPC-H:
- Raw : dados CSV gerados com a ferramenta tpch-dbgen. A versão bruta do conjunto de dados é de 100 GB e as maiores tabelas (LINEITEM é de 76 GB e ORDERS de 16 GB) são divididas em 80 arquivos.
- Parquets sem divisórias : CSVs são convertidos em Parquets com Athena CTAS. Esta versão do conjunto de dados tem 31,5 GB e as maiores tabelas (o LINEITEM tem 21 GB e os ORDERS são 4,5 GB) também são divididos em 80 arquivos.
- Parquets Particionados : as maiores tabelas – LINEITEM e ORDERS – são particionadas por colunas de data com Glue; o resto das tabelas são deixadas sem partições. Esta versão do conjunto de dados tem 32,5 GB e as maiores tabelas, que são particionadas (LINEITEM é 21,5 GB e ORDERS são 5 GB), possuem uma partição por dia; cada partição tem um arquivo. Existem cerca de 2.000 partições para cada tabela.
Essas 3 versões do mesmo conjunto de dados serão usadas em nossos próximos blogs. Fique ligado!
Conclusão
Neste blog, discutimos como otimizar data lakes usando Parquets e mecanismos de otimização, como particionamento. Também introduzimos o conceito de data lakehouse, uma palavra da moda que chega ao mercado agora e baseada na ideia de consultar data lakes combinando-os conceitualmente com data warehouses.
Também demonstramos como converter CSVs em Parquets particionados na AWS. Vimos que a maneira mais fácil e barata de criar um arquivo Parquet a partir de um arquivo bruto, como CSV ou JSON, é usando o Athenas CTAS. No entanto, quando também queremos particionar os dados, o Athena limita-se a um máximo de 100 partições; isso pode ser resolvido usando várias instruções INSERT ou usando um trabalho Glue com PySpark DataFrames.
Nas próximas postagens do blog desta série, usaremos diferentes tecnologias de consulta de data lake para carregar e consultar as 3 versões do conjunto de dados que criamos aqui. Em seguida, poderemos avaliar o impacto do uso de formatação adequada para um data lake.
Aqui na ClearPeaks, nossos consultores possuem ampla experiência com AWS e tecnologias de nuvem, portanto, não hesite em nos contatar se quiser saber mais sobre essas tecnologias e quais são mais adequadas para você.
Fonte: clearpeaks