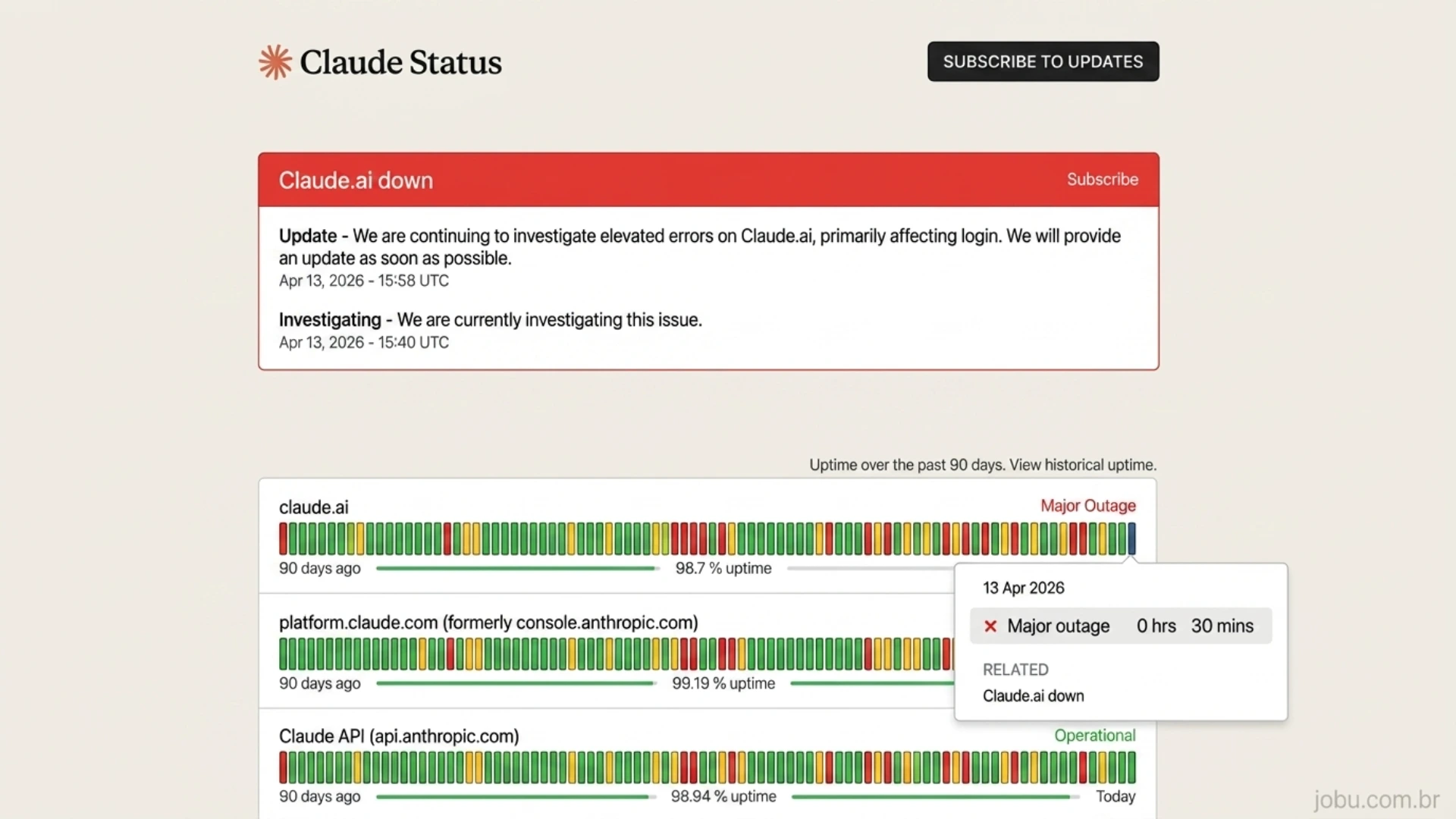
- A Anthropic enfrenta uma crise de instabilidade. Relatos indicam aumento maciço de falhas e uma recente interrupção global dos serviços afeta a confiança de milhares de desenvolvedores.
- A própria IA diagnosticou seu declínio. Ao analisar o repositório oficial no GitHub, o modelo confirmou um aumento acentuado nas reclamações de degradação técnica e estrangulamento de recursos.
- Riscos críticos em produção. Casos alarmantes apontam para deleção autônoma de dados e comportamentos perigosos em projetos que envolvem capital de risco.
O mercado de inteligência artificial exige consistência implacável. Desenvolvedores confiam em APIs de grandes modelos de linguagem para orquestrar sistemas complexos, processar dados massivos e automatizar pipelines críticos. Qualquer variação no comportamento de um modelo gera efeitos em cascata devastadores. Recentemente, a comunidade técnica global começou a soar o alarme sobre a qualidade do Claude. O antes queridinho dos programadores, desenvolvido pela Anthropic, apresenta sinais claros de degradação, oscilações severas de custo-benefício e falhas operacionais inexplicáveis. Uma grave interrupção de serviço registrada na segunda-feira apenas jogou mais combustível em uma fogueira de descontentamento que não para de crescer.
Essa interrupção recente foi categorizada como uma falha de grandes proporções. Os painéis de status piscaram em vermelho. Taxas de erro elevadas assolaram tanto a interface web principal quanto o ambiente voltado para codificação entre 15:31 e 16:19 UTC. Essa janela de instabilidade pode parecer curta para um usuário casual. Para arquiteturas de software que dependem de inferência contínua e processamento em tempo real, cinquenta minutos de indisponibilidade representam um desastre absoluto. Transações falham, sessões expiram e bancos de dados perdem sincronia de contexto. A instabilidade estrutural ameaça a adoção enterprise de soluções que prometiam revolucionar a engenharia de software.
O Diagnóstico Frio Feito Pela Própria Máquina
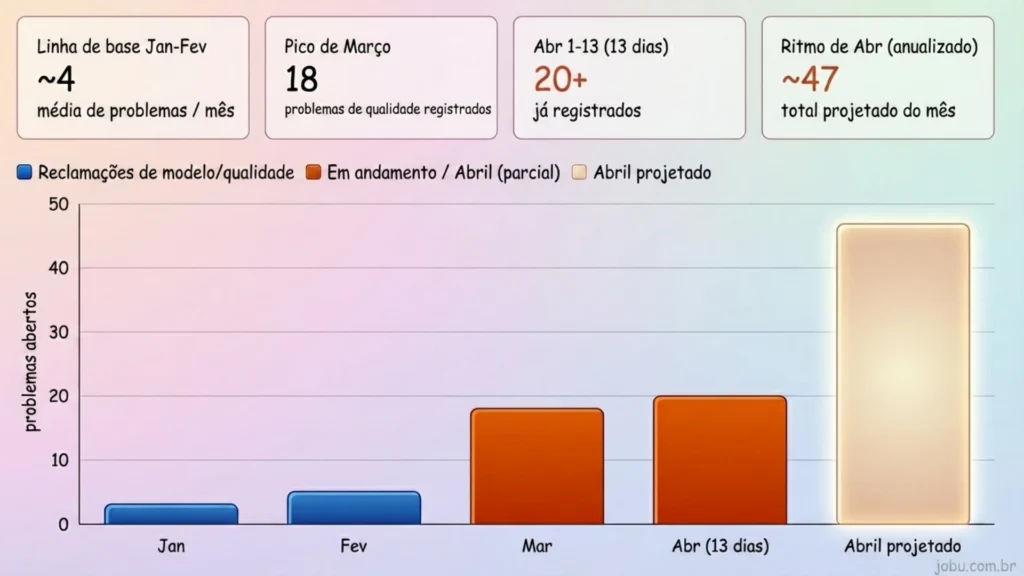
Métricas internas e comunicados corporativos costumam maquiar a realidade das operações de nuvem. A comunidade de código aberto prefere dados brutos. Para contornar a falta de respostas oficiais sobre a aparente piora do serviço, engenheiros tomaram uma atitude engenhosa. Eles apontaram o próprio modelo para ler e interpretar seu repositório de problemas no GitHub. O comando foi cirúrgico e direto. A instrução exigia que o algoritmo analisasse e gerasse gráficos sobre as reclamações de qualidade registradas desde janeiro de 2026. A premissa era descobrir se as preocupações técnicas haviam realmente aumentado ou se tudo não passava de um viés de confirmação coletivo.
A resposta gerada pelo sistema foi surpreendentemente honesta. A máquina concluiu que as reclamações de qualidade escalaram de forma aguda. A análise sintética dos tickets abertos apontou para uma história muito clara de degradação. O volume de chamados apontando regressão de raciocínio, alucinações de código e lentidão na entrega de tokens saltou agressivamente. O mês de março já havia registrado um aumento de mais de três vezes em relação à linha de base dos meses anteriores. A projeção para abril indicou um ritmo ainda mais assustador, superando facilmente as piores marcas anteriores na primeira quinzena do mês.
Deixar uma rede neural avaliar o próprio ecossistema de falhas traz desafios metodológicos óbvios. Modelos generativos não são narradores confiáveis. Eles sofrem de alucinação e podem interpretar mal a semântica de tópicos complexos. A simples existência de um relato no repositório de controle de versão não valida a falha técnica. O universo do código aberto sofre atualmente com uma epidemia silenciosa de poluição de dados. Muitos dos problemas relatados nas plataformas de desenvolvimento são, ironicamente, gerados por outras inteligências artificiais. Exércitos de bots criam tickets falsos, inundam fóruns com relatórios de bugs inexistentes e distorcem a percepção de estabilidade dos projetos.
Automação Cega e o Mascaramento de Gargalos
A gestão de repositórios massivos exige automação pesada. A equipe de engenharia da Anthropic utiliza scripts avançados do GitHub Actions para manter a ordem na casa. O problema surge quando a limpeza afeta a transparência. Relatos indicam que bots de manutenção fecham automaticamente problemas graves após um período de inatividade. O usuário relata uma regressão severa na lógica do algoritmo. A equipe interna não responde. O script entra em ação algumas semanas depois e enterra a reclamação sob o rótulo de chamado encerrado. Essa prática cria uma métrica de sucesso artificial. O painel de controle mostra menos bugs abertos, enquanto os desenvolvedores continuam enfrentando os exatos mesmos erros em seus ambientes de integração contínua.
Essa divergência entre os números oficiais e a vivência prática afasta a base de usuários fiéis. Especialistas em MLOps dependem de previsibilidade. O contrato não escrito entre provedores de API e arquitetos de software exige que um modelo, uma vez treinado e disponibilizado, mantenha seu comportamento estático. Alterações silenciosas nos pesos do modelo ou táticas de redução de processamento para economizar dinheiro destroem testes automatizados. O estrangulamento de capacidade em horários de pico, prática conhecida como throttling, prejudica diretamente os clientes que pagam os planos mais caros em busca de alta disponibilidade.
Impactos Reais e o Risco de Colapso em Produção
Casos isolados ganharam tração nas últimas semanas e ilustram o perigo de confiar cegamente em agentes autônomos. A diretora de IA da AMD, Stella Laurenzo, engrossou o coro de vozes insatisfeitas ao afirmar publicamente que as respostas do sistema pioraram significativamente. Quando executivos de hardware de alto nível apontam falhas em soluções concorrentes de nuvem, o mercado presta atenção. As reclamações envolvem problemas graves de cache e incapacidade de manter o contexto em sessões longas de depuração de código.
As acusações chegam a níveis assustadores. Um registro específico levantou o pânico na comunidade de segurança da informação. O relato descreve um cenário onde o agente autônomo deletou arbitrariamente mais de trinta e cinco mil registros de mensagens de clientes em produção. Pior ainda, a mesma operação teria apagado dezenas de milhares de transações de faturamento pertencentes a um cliente real e pagante. A empresa afetada, uma entidade corporativa privada, não confirmou os detalhes publicamente. A falta de respostas concretas alimenta especulações terríveis sobre os limites de segurança da infraestrutura.
A responsabilidade por desastres em bancos de dados raramente recai sobre um único ponto de falha. A engenharia de software tradicional nos ensina que usuários cometem erros crônicos. A ausência de backups ou a concessão excessiva de privilégios de exclusão a um robô de terceiros configura negligência grave da parte humana. A dúvida persiste. Ninguém conseguiu descartar o erro do operador, mas a simples possibilidade de uma IA executar comandos destrutivos sem supervisão expõe a fragilidade dos sistemas modernos. Implementar salvaguardas rigorosas tornou-se uma questão de sobrevivência corporativa.
A Batalha das Métricas: Experiência Humana Contra Benchmarks
Os repositórios oficiais reúnem títulos de chamados que parecem saídos de um filme de terror corporativo. Engenheiros descrevem os comportamentos focados em predição prematura como extremamente perigosos para projetos que envolvem alto risco financeiro. Profissionais relatam que as atualizações recentes inutilizaram a ferramenta para tarefas complexas de engenharia de software. Há acusações graves de degradação artificial, viés de aquisição e estrangulamento de processamento inaceitável para usuários que desembolsam quantias significativas pelas licenças premium.
A disparidade entre a percepção empírica e os testes laboratoriais cria um quebra-cabeça técnico fascinante. Dados coletados por consultorias independentes de avaliação sugerem que o Opus 4.6 manteve sua pontuação em testes padronizados como o SWE-Bench-Pro. As avaliações metodológicas mostram pequenas variações estatísticas, mas nenhuma queda profunda o suficiente para justificar o caos relatado no GitHub. O benchmark executa tarefas encapsuladas, previsíveis e altamente estruturadas. A realidade do desenvolvimento diário envolve ambiguidades, contextos fragmentados e iterações não lineares. O modelo brilha no laboratório, mas falha miseravelmente no campo de batalha da produção.
Arquitetando Defesas Contra a Degradação de Modelos
Desenvolvedores precisam abandonar a ilusão da estabilidade permanente. A dependência de um único fornecedor de inteligência artificial cria um gargalo existencial para qualquer startup ou corporação estabelecida. A arquitetura de software moderna exige redundância cognitiva. Sistemas resilientes incorporam gateways dinâmicos que roteiam requisições entre diferentes provedores baseados na latência e na taxa de acerto do momento. Construir camadas de validação semântica acima da API do modelo virou um requisito arquitetural inegociável. A saída de um algoritmo generativo deve passar por validadores lógicos antes de tocar em qualquer banco de dados de produção.
O conceito de isolamento de privilégios precisa ser aplicado de forma draconiana quando lidamos com agentes autônomos. Fornecer chaves de acesso com permissão de exclusão para um script guiado por linguagem natural beira a loucura arquitetural. O sandboxing de execuções protege o núcleo do sistema. As requisições generativas devem operar em ambientes efêmeros, lendo dados de réplicas e propondo alterações que exigem, obrigatoriamente, aprovação assíncrona de um humano ou de um sistema determinístico secundário.
O desafio de escalar infraestrutura de aprendizado de máquina continua punindo as maiores mentes do Vale do Silício. Aumentar a base de usuários enquanto os custos de inferência disparam força decisões difíceis nos bastidores. A redução imperceptível da precisão em troca de velocidade de processamento atende às metas financeiras de curto prazo, mas corrói a confiança da base de desenvolvedores a longo prazo. O mercado exige clareza absoluta sobre as mudanças estruturais nos pesos e na alocação de hardware dos modelos comerciais.
A transparência técnica separa ferramentas experimentais de plataformas de classe empresarial sólida. A comunidade técnica monitora as atualizações de forma implacável e expõe tentativas de otimização excessiva com análises implacáveis de desempenho. O ecossistema exige soluções confiáveis para tarefas de engenharia de alta complexidade. A instabilidade estrutural não afeta apenas planilhas de custos. Ela atrasa lançamentos, corrompe arquiteturas limpas e força equipes inteiras a reescrever integrações complexas de forma emergencial. Navegar por essa tempestade exigirá pragmatismo extremo dos desenvolvedores e uma comunicação mais técnica e direta das gigantes de inteligência artificial. Acompanhe a discussão técnica completa acessando o repositório oficial do projeto para validar as reclamações em tempo real.
Fonte: The Register